
Page 199 - 《软件学报》2021年第12期
P. 199
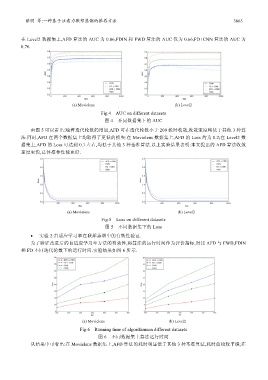
谌明 等:一种基于注意力联邦蒸馏的推荐方法 3863
在 Level2 数据集上,AFD 算法的 AUC 为 0.86,FDIN 和 FWD 算法的 AUC 仅为 0.66,FD+CNN 算法的 AUC 为
0.76.
(a) Movielens (b) Level2
Fig.4 AUC on different datasets
图 4 不同数据集下的 AUC
由图 5 可以看出:随着迭代轮数的增加,AFD 可在迭代轮数小于 200 轮时收敛,收敛速度略优于其他 3 种算
法.同时,AFD 在两个数据集上均取得了更低的损失:在 Movielens 数据集上,AFD 的 Loss 约为 0.2;在 Level2 数
据集上,AFD 的 Loss 可达到 0.1 左右,均低于其他 3 种基准算法.以上实验结果表明:本文提出的 AFD 算法收敛
速度更快,总体推荐性能更好.
(a) Movielens (b) Level2
Fig.5 Loss on different datasets
图 5 不同数据集下的 Loss
• 实验 2:自适应学习率在联邦蒸馏中的有效性验证.
为了验证改进后的自适应学习率方法的有效性,将算法的运行时间作为评价指标,对比 AFD 与 FWD,FDIN
和 FD 不同迭代轮数下的运行时间.实验结果如图 6 所示.
(a) Movielens (b) Level2
Fig.6 Running time of algorithmson different datasets
图 6 不同数据集上算法运行时间
从结果中可看出:在 Movielens 数据集上,AFD 算法的耗时明显低于其他 3 种基准算法,耗时曲线较平缓;在