
Page 133 - 《软件学报》2021年第12期
P. 133
孔芳 等:篇章视角的汉语零指代语料库构建 3797
Boundary2
end
Pointing
Phase
O O O O O B
Boundary1
Boundary
distribution
O O B
L L
BiLSTM S S
Encoder T T
hidden M M
states
Decoding
一 是 继续 鼓 励 和 支 持 外 来 投 资 , Phase
start 继续
Training:Teacher forcing
Test:Copy boundary neighbor
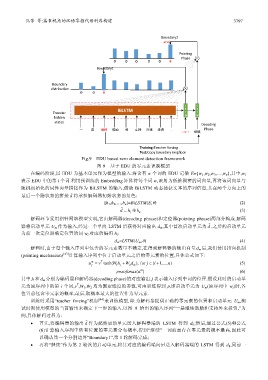
Fig.9 EDU based zero element detection framework
图 9 基于 EDU 的零元素识别框架
在编码阶段,以 EDU 为基本单元作为模型的输入.将含有 n 个词的 EDU 记做 E={w 1 ,w 2 ,w 3 ,…,w n },其中,w i
表示 EDU 中的第 i 个词.利用预训练的 Embedding 矩阵将每个词 w i 映射为低维稠密的词向量,再将该词向量与
随机初始化的词性向量拼接作为 BiLSTM 的输入,借助 BiLSTM 动态捕获文本的序列信息,其在两个方向上的
最后一个隐状态的拼接 d 将承担解码器初始状态的角色:
[h 1 ,h 2 ,…,h n ]=BiLSTM(E,θ) (2)
d = h ⊕ G h G (3)
1 n
解码环节采用指针网络模型实现,它由解码器(decoding phrase)和定位器(pointing phrase)两部分构成.解码
器将启动单元 U m 作为输入,经过一个单向 LSTM 后获得对应输出 d m ,其中首次启动单元为 d ,之后的启动单元
为前一次定位器确定位置的词 w i 对应的编码 h i :
d m =LSTM(U m ,θ) (4)
解码时,由于每个输入序列中包含的零元素数量不确定,在得到解码器的输出向量 d m 后,我们使用指向机制
(pointing mechanism) [43] 计算输入序列中位于启动单元之后的零元素的位置,具体公式如下:
u = m j v T tanh(W h + 1 j W d ), for j ∈ (i + 1,..., )n (5)
2 m
m
p=softmax(u ) (6)
其中,h 和 d m 分别为编码层和解码器(decoding phase)的对应输出,j 表示输入序列中词的位置.假设此时的启动单
T
元为原序列中的第 i 个词,v ,W 1 ,W 2 均为固定维度的参数,可由训练得到 p,即启动单元为 U m (原序列中 w i )时,各
位置前包含零元素的概率,最后,取概率最大的位置作为零元素.
训练时采用“teacher forcing”机制 [44] 来训练模型,即:为解码器提供正确的零元素的位置和启动单元 U m ,测
试时则使用模型的当前输出来确定下一步的输入.以图 9 给出的输入序列“一是继续鼓励和支持外来投资,”为
例,具体解码过程为:
• 首先,将编码器的输出 d 作为起始启动单元送入解码器端的 LSTM 得到 d 0 ;然后,通过公式(5)和公式
(6)计算输入序列中所有位置的零元素分布概率,得到“继续”一词前面存在零元素的概率最高,因此可
以确认第一个分割边界“Boundary1”,第 1 轮解码完成;
• 再将“继续”作为第 2 轮次的启动单元,将其对应的编码端向量送入解码器端的 LSTM 得到 d 8 ,同前一