
Page 180 - 《软件学报》2021年第11期
P. 180
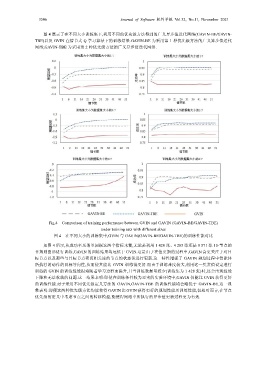
3506 Journal of Software 软件学报 Vol.32, No.11, November 2021
图 4 展示了在不同大小训练集下,利用不同的优先级方法得到的广义异步值迭代网络(GAVIN-BE/GAVIN-
TBE)以及 GVIN 在情节式 Q 学习算法下的训练结果.GAVIN-BE 为采用第 1 种优先级方法的广义异步值迭代
网络;GAVIN-TBE 为采用第 2 种优先级方法的广义异步值迭代网络.
Fig.4 Comparison of training performance between GVIN and GAVIN (GAVIN-BE/GAVIN-TBE)
under training sets with different sizes
图 4 在不同大小的训练集中,GVIN 与 GAVIN(GAVIN-BE/GAVIN-TBE)的训练性能对比
如图 4 所示,从成功率及期望回报这两个指标来看,无论是利用 1 428 张、4 285 张还是 8 571 张 10-节点的
非规则图形进行训练,GAVIN 的训练结果均远优于 GVIN.这是由于在值更新的过程中,GAVIN 会更关注于对目
标节点以及那些与目标节点密切相关连的节点的状态值进行更新.这一特性增强了 GAVIN 规划过程中智能体
所执行的动作的目标导向性,从而使其能比 GVIN 训练得更好.而由于训练难度较大,利用这一奖赏值设定进行
训练的 GVIN 的训练性能很难随着学习过程而提升,且当训练数据量较少(训练集为 1 428 张)时,还会出现性能
下降和无法收敛的问题.这一结果表明:即使在训练条件较为恶劣的实验环境中,GAVIN 仍能比 GVIN 获得更好
的训练性能.对于采用不同优先级定义方法的 GAVIN,GAVIN-TBE 的训练性能均会略优于 GAVIN-BE.这一现
象表明:即便这两种优先级方法均能使得 GAVIN 比 GVIN 获得更好的规划性能及训练性能,但相对而言,在节点
优先级的定义中考虑节点之间的转移模型,能使得网络中所执行的异步值更新过程更为有效.