
Page 74 - 《软件学报》2021年第10期
P. 74
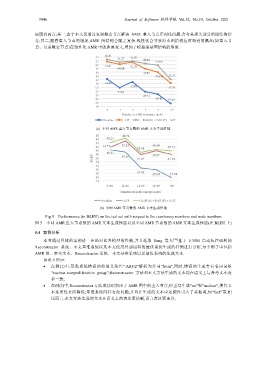
3046 Journal of Software 软件学报 Vol.32, No.10, October 2021
原因有两点:其一,由于本文仅通过复制概念节点解决 AMR 重入节点序列化问题,会令其损失部分的图结构信
息;其二,随着重入节点的增加,AMR 图结构会随之复杂,线性化会导致原本图结构位置相近的概念(如重入节
点、兄弟概念节点)在线性化 AMR 中的距离变大,增加了模型捕获图结构的难度.
(a) 不同 AMR 重入节点数的 AMR 文本生成性能
(b) 不同 AMR 节点数的 AMR 文本生成性能
Fig.5 Performance (in BLEU) on the test set with respect to the reentrancy numbers and node numbers
图 5 不同 AMR 重入节点数的 AMR 文本生成性能以及不同 AMR 节点数的 AMR 文本生成性能(在 BLEU 上)
5.4 案例分析
本节通过具体的案例进一步地对比各模型的性能,并且选取 Song 等人 [26] 基于 0.39M 自动标注语料的
Reconstructor 系统、本文基准系统以及本文使用外部语料的最优系统生成的样例进行分析,每个例子中包括
AMR 图、参考文本、Reconstructor 系统、本文基准系统以及最优系统的生成文本.
如表 6 所示:
在例(1)中,基准系统错误地将语义角色“:ARG2”解析为介词“from”,同时,错误地生成专有名词词组
“nuclear nonproliferation group”;Reconstructor 方法和本文方法生成的文本均在语义上与参考文本近
乎一致;
在例(2)中,Reconstructor 方法成功识别出了 AMR 图中的重入节点,但重复生成“no”和“nuclear”,使得文
本连贯性有所降低;基准系统同样有此问题,并且在生成的文本中还额外引入了其他词,如“fact”等;相
比而言,本文方法生成的文本在语义上的表达更清晰,语言表达更连贯;