
Page 305 - 《软件学报》2021年第9期
P. 305
吴森焱 等:融合多种特征的恶意 URL 检测方法 2929
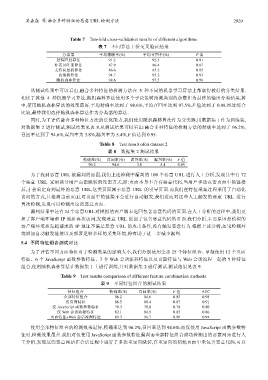
Table 7 Ten-fold cross-validation results of different algorithms
表 7 不同算法十折交叉验证结果
分类器 平均精确率(%) 平均召回率(%) F 值
逻辑回归算法 91.2 92.3 0.91
朴素贝叶斯算法 87.9 86.4 0.87
支持向量机算法 86.6 85.2 0.85
决策树算法 94.7 93.2 0.93
随机森林算法 98.6 97.5 0.98
从测试结果中可以看出,融合多种特征的检测方法在 5 种不同的机器学习算法上都取得较好的分类结果.
相比于其他 4 种机器学习算法,随机森林算法使用多个子决策树预测类别的众数作为最终的输出分类结果,其
中,使用随机森林算法的效果最好,平均精确率达到了 98.6%,平均召回率达到 97.5%,F 值达到了 0.98.经过综合
比较,最终我们选择随机森林算法作为分类器的算法.
同时,为了评估融合多种特征方法的泛化能力,我们使用随机森林算法作为分类器,用数据集 1 作为训练集,
对数据集 2 进行测试,测试结果见表 8.从测试结果可以看出:融合多种特征的检测方法的精确率达到了 96.2%,
召回率达到了 94.6%,误判率为 3.8%,漏判率为 5.4%,F 值达到 0.95.
Table 8 Test result ofon dataset 2
表 8 数据集 2 测试结果
精确率(%) 召回率(%) 误判率(%) 漏判率(%) F 值
96.2 94.6 3.8 5.4 0.95
为了找到恶意 URL 被漏判的原因,我们上述检测中漏判的 108 个恶意 URL 进行人工分析,发现其中有 72
个恶意 URL 采用诱导用户点击跳转的攻击方式,即:页面本身不含有恶意代码,当用户手动点击页面中的链接
后,才会重定向到最终的恶意 URL,这类页面属于恶意 URL 的引导页面.而我们在特征采集过程采用了自动化
访问的方式,只检测当前页面,对页面中的链接不会进行自动触发,我们进而对这些人工触发的恶意 URL 进行
再次检测,发现可以检测出这些恶意页面.
漏判结果中还有 24 个恶意 URL对模拟的客户端未返回包含恶意代码的页面.在人工分析的过程中,我们更
换了客户端环境和 IP 地址再次访问,发现恶意 URL 返回了包含恶意代码的页面.我们分析,主要原因是模拟的
客户端环境和发起请求的 IP 地址不满足恶意 URL 的攻击条件,没有触发恶意行为.根据上述分析,如果检测环
境增加自动触发链接以及部署足够多样的采集环境,将有助于进一步减少漏判.
5.4 不同特征组合测试对比
为了评估不同方面特征对于检测效果的影响大小,我们分别使用全部 25 个特征组合、单独使用 12 个页面
特征、6 个 JavaScript 函数参数特征、7 个 Web 会话流程特征以及页面特征与 Web 会话流程一起的 5 种特征
组合,使用随机森林算法在数据集 1 上进行训练,并对数据集 2 进行测试.测试结果见表 9.
Table 9 Test results comparison of different feature combination methods
表 9 不同特征组合的测试结果
特征组合 精确率(%) 召回率(%) F 值 AUC
全部特征组合 96.2 94.6 0.95 0.98
仅页面特征 86.5 88.4 0.87 0.91
仅 JavaScript 函数参数特征 78.3 76.8 0.78 0.80
仅 Web 会话流程特征 82.1 84.5 0.83 0.86
页面特征+Web 会话流程特征 89.3 91.7 0.90 0.94
使用全部特征组合的检测效果最好,精确率达到 96.2%,召回率达到 94.6%;而仅使用 JavaScript 函数参数特
征时,检测效果最差.我们对仅使用 JavaScript 函数参数特征漏判而全部特征组合成功检测出的恶意网站进行人
工分析,发现这些恶意网站在会话过程中进行了多次重定向跳转,在重定向的初始页面中未包含恶意代码,可以