
Page 271 - 《软件学报》2021年第8期
P. 271
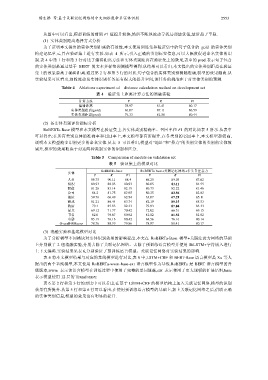
琚生根 等:基于关联记忆网络的中文细粒度命名实体识别 2553
从图中可以看出,模型训练的前期 F1 值提升较快,然后不断地波动寻找局部最优值,最后趋于平稳.
(1) 实体类别距离选择方式分析
为了证明本文提出的实体类别距离的有效性,本文使用训练集和验证集中的句子包含的 gold 的实体类别
构建记忆单元,并在验证集上进行实验.如表 4 所示,引入正确的类别标签信息,可以大幅度促进命名实体的识
别.表 4 中第 1 行和第 3 行对比了编辑距离方法和实体类别距离在验证集上的效果,表中的 pred 表示句子包含
的实体类别是通过基于 BERT 的文本多标签预测模型得到.从结果可以看出,本文提出的实体类别距离在验证
集上的效果要高于编辑距离.通过第 2 行和第 3 行的对比,句子包含的实体类别预测越准确,模型的效果越高.从
实验结果可以看出,细粒度命名实体识别任务还有很大的提升空间,该任务的挑战在于对实体类别的预测.
Table 4 Ablations experiment of distance calculation method on development set
表 4 验证集上距离计算方法的消融实验
计算方法 P R F1
编辑距离 78.97 81.41 80.17
实体类别距离(gold) 86.07 87.11 86.59
实体类别距离(pred) 79.33 81.58 80.44
(2) 各实体类别评价指标分析
RoBERTa-Base 模型和本文模型在验证集上,各实体类别精确率、召回率和 F1 的对比如表 5 所示.从表中
可以得出:在所有类别总体的准确率和召回率上,本文模型都有所提升.在各类别的召回率上,本文模型都较高,
说明本文模型能多识别更多的命名实体.从表 5 可以看出,模型对“地址”和“景点”的类别实体的类别的实体效
果差,模型的效果取决于对这两种类别实体的识别和区分.
Table 5 Comparison of models on validation set
表 5 验证集上的模型对比
RoBERTa-base RoBERTa-base+关联记忆网络+多头自注意力
实体
P R F1 P R F1
人名 86.75 90.11 88.4 86.25 89.03 87.62
组织 80.93 80.93 80.93 80.05 83.11 81.55
职位 81.26 83.14 82.19 80.73 82.22 81.46
公司 84.2 81.75 82.95 80.25 83.86 82.02
地址 59.76 66.49 62.94 63.07 67.29 65.11
游戏 81.21 86.44 83.74 82.19 89.15 85.53
政府 79.1 85.83 82.33 79.93 87.04 83.33
景点 69.12 71.77 70.42 72.02 66.51 69.15
书名 82.0 79.87 80.92 81.82 81.82 81.82
电影 85.19 76.16 80.42 84.56 76.16 80.14
Overall@Macro 78.76 80.99 79.86 78.97 81.41 80.17
(3) 消融实验和基线模型对比
为了分析模型不同模块对实体识别效果的影响程度,本文在 RoBERTa-Base 模型+关联注意力网络的基础
上分别做了 2 组消融实验,分别去除了关联记忆网络、去除了预训练语言模型并使用 BiLSTM+字符嵌入进行
上下文编码.实验结果见表 6,分别验证了预训练语言模型、关联记忆网络对实验结果的影响.
表 6 将本文模型结果与对应的基线模型进行对比,表 6 中,LSTM+CRF 和 BERT-Base 语言模型是 Xu 等人
提出的两个基线模型,本文使用 RoBERTa-wwm-base-ext 语言模型作为基线.RoBERTa 是 BERT 语言模型的升
级版本,wwm 表示该语言模型在训练过程中使用了完整的单词遮蔽,ext 表示使用了更大规模的扩展语料,base
表示模型使用 12 层的 Transformer.
表 6 第 2 行和第 3 行的对比中可以看出,在基于 LSTM+CRF 的模型结构上加入关联记忆网络,模型的识别
效果有所提升.从第 5 行和第 6 行可以看出,在使用预训练语言模型的基础上,加上关联记忆网络之后,借助正确
的实体类别信息,模型的效果也有明显的提升.