
Page 268 - 《软件学报》2021年第8期
P. 268
2550 Journal of Software 软件学报 Vol.32, No.8, August 2021
M = [a 1, j ,a 2, j ,...,a , s l j ] (5)
j
其中,f(⋅)代表 softmax 函数,a i,j 是 M raw 矩阵第 i 行的简化形式.
j
标签序列的融入和合并如式(6)所示,是将归一化后的注意力矩阵 M j 与记忆句子对应的标签嵌入序列 L j
相乘后,得到融入了标签信息的序列 L′ ,它根据输入句子 s 中的每个字符对记忆句子中每个字符标签的关注程
j
度来计算输入句子中每个字符对应的标签类别信息:
] , j ∈
L′ = j [a ⋅ , i j L T j i= s l 1 {1,2,..., }n (6)
最后,将 n 个融入了标签信息的序列 L′ 进行平均,并与句子 s 的上下文向量 s′拼接,得到最后的输入句子表
j
示 e,如式(7)所示.
e = [, s mean L′ (7)
′
( )]
j
d+l
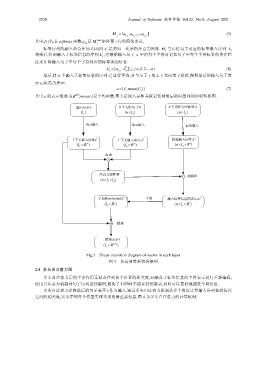
其中,e 的表示维度为\ ,mean(⋅)是平均函数.图 3 是嵌入层和关联记忆网络层的向量间的形状转换图.
输入句子s n 个记忆句子a n 个记忆句子标签 L
()l s (nl× a ) (nl× a )
Bert嵌入 Bert嵌入 标签嵌入
上下文嵌入向量 s′ 上下文嵌入向量 a′ 标签嵌入向量 L′
(l × R d ) (l × R d ) (nl×× R l )
a
s
a
点乘
注意力矩阵M 加权和
(nl×× l )
s a
平均表示mean (a L ) 平均 融入标签信息的表示a L
(l × R l ) (nl×× R l )
s s
拼接
拼接表示e
(l × R dl+ )
s
Fig.3 Shape transition diagram of vector in each layer
图 3 各层向量形状转换图
2.4 多头自注意力层
多头自注意力层的主要作用是结合序列各个位置的相关度,对融合了标签信息的字符表示进行重新编码,
使用自注意力机制对句子序列进行编码,避免了 LSTM 不能并行的缺点,同时可以更好地捕获全局信息.
多头自注意力层将最后的句子表示 e 作为输入,通过多头自注意力机制从多个角度计算输入序列任意位置
之间的相关度,突出序列每个位置实体类别的最重要信息.图 4 为多头自注意力的计算机制.