
Page 131 - 《软件学报》2021年第8期
P. 131
杨世贵 等:基于强化学习的温度感知多核任务调度 2413
Fig.3 Comparison of the same reward function under different environmental state models
图 3 相同奖励函数,不同环境状态模型下的对比
Fig.4 Comparison of the same environment state model and different reward functions
图 4 相同环境状态模型,不同奖励函数下的对比
3.2 DSM
本文还研究了当前另一种基于强化学习的温度管理算法 [20] ,后文中简称该方法为 DSM.在 DSM 中,作者使
用两个指标:热应力(由于温度变化使得芯片在各种约束下所有的应力反应)和老化程度作为最小化温度的环境
状态,并将这两个指标加入到奖励函数的计算结果中.该方法采用了一个较为复杂的动作空间,同时对任务进行
调度并相应地主动调节系统频率.在奖励函数中,DSM 将延迟考虑进去,通过加入延迟约束来同时优化温度和
保证延迟.然而通过实验发现,此方法并不能在这温度和性能两者之间达到一个很好的平衡.使用之前相同的计
算平台,采用 DSM 方法调度程序 facesim 进行实验,选择 test 为程序的输入集,因 DSM 需要加入一个约束延迟,
通过实验测试 facesim 在本次实验环境下的最低运行时间为 4.0s,最高运行时间为 19.0s.我们选择将 DSM 的延
迟设置为 5s,反复调用 1 200 次.
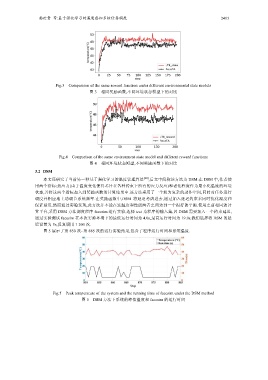
图 5 展示了第 850 次~第 885 次的运行实验结果,包含了程序运行时间和系统温度.
Fig.5 Peak temperature of the system and the running time of facesim under the DSM method
图 5 DSM 方法下系统的峰值温度和 facesim 的运行时间