
Page 337 - 《软件学报》2021年第7期
P. 337
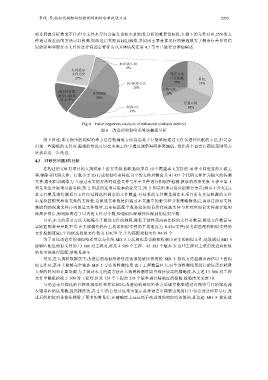
李玫 等:面向代码相似性检测的相似哈希改进方法 2255
哈希同源分析效果不佳,但小文件本身包含语义也较少,相似性分析的重要性较低.在剩下的文件对中,25%的文
件通过改进前的方法可以检测,而改进后其距离超出阈值,其原因主要是常见行的筛选放大了剩余行差异对结
果的影响和部分小文件经过行筛选后特征为 0,具体情况在第 4.1 节中已进行过详细阐述.
Fig.6 False negatives analysis of enhanced simhash method
图 6 改进后相似哈希算法漏报分析
综上所述,本文提出的相似哈希方法在精确度方面远远高于只简单地通过文件名进行匹配的方法,但是会
出现一些漏报的文件对.漏报的情况可以在未来工作中通过调整海明距离阈值、优化各个语言行筛选范围等方
法加以进一步改进.
4.3 对研究问题3的分析
在构建的 130 万项目的大规模库上进行实验,随机抽取来自 10 个覆盖本文支持的 10 种不同语言的开源工
程,筛除非代码文件、行数小于 20 行或相似哈希特征为空的文件后剩余共 41 437 个代码文件作为输入的待测
文件,海明距离阈值为 3.通过本文的方法对这些文件与库中文件进行相似性检测,获取的结果见表 8.表中第 1
列是所选开源项目的名称,第 2 列是所选项目版本的提交号,第 3 列是指项目包含的部分语言(排名不分先后).
总文件数是指待测项目文件经过筛选后剩余的文件数量.有结果的文件数是指在本项目所有参与检测的文件
中最终匹配到相似文件的文件数.总候选文件数是指通过本文建立的索引和分表策略筛选后,该项目所有文件
获取到的候选文件序列的总文件数量.总实际匹配个数是指该项目所有候选文件与其对应项目文件进行海明
距离计算后,海明距离在 3 以内的文件对个数,即相似匹配最终匹配到的结果个数.
可见,本文的索引方法大幅缩小了候选文件的规模,降低了最终需两两比较的文件对数量,候选文件数量与
实际匹配数量差距不大.在大规模代码库上检索相似文件的平均速度为 0.43s/文件(仅考虑匹配到相似文件的
文件检测速度),平均候选相似文件数为 124.78 个,平均匹配相似文件 94.38 个.
为了对比改进后的相似哈希算法与传统 MD 5 方法相比是否能够检测出更多的相似文件,选取通过 MD 5
能够匹配出相似文件的 13 886 对工程对,涉及 4 589 个工程、45 383 个版本.在这些工程对上采用改进后相似
哈希方法进行匹配,结果见表 9.
可见,在大规模数据集下,改进后的相似哈希算法依旧能够比传统的 MD 5 指纹方法检测出两倍以上的相
似文件对,基本上能够完全覆盖 MD 5 方法的检测结果.由于工程数量巨大,对全部检测结果进行验证需要耗费
大量的时间和计算资源.为了验证本文所提方法在大规模检测时能否保持较高的精确度,从上述 13 886 对工程
文件中随机抽取了 309 对工程对,涉及 124 个工程的 218 个版本进行精确度的检验.检验结果见表 10.
与完全无行筛选的行粒度相似哈希算法相比,改进前的相似哈希方法确实能够通过对纯符号行的筛选减
少错误匹配结果数,提高精度值,表 2 中的行统计结果也显示各种语言中频繁出现的行中包含部分纯符号行.改
进后的相似哈希算法筛除了更多的常见行,在精确度上远远高于改进前的相似哈希算法,且比起 MD 5 算法能