
Page 306 - 《软件学报》2021年第7期
P. 306
2224 Journal of Software 软件学报 Vol.32, No.7, July 2021
(M-CE-Inv)的自动计算,其中,这两个特征从不同角度刻画了软件模块的自然性;最后将由此得到的新度量元与
其他特征相结合,一同执行软件缺陷预测任务,其中,CNDePor 的预测目标为软件模块的缺陷倾向性.
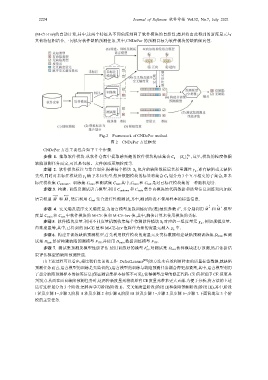
Fig.2 Framework of CNDePor method
图 2 CNDePor 方法框架
CNDePor 方法主要包含如下 7 个步骤.
步骤 1. 抽取软件模块.从软件仓库中提取感兴趣的软件模块构成集合 C {} ,S kk N C 这里,模块的粒度依据
0
缺陷预测任务而定,可以是包级、文件级或更细粒度等.
,
步骤 2. 软件模块标注与集合划分.根据每个模块 S k 包含的缺陷数标记其质量属性 即有缺陷或无缺陷
k
类型,同时对未标注模块的 赋予未知类型.然后依据模块的标签将集合 C 0 划分为 3 个互不相交的子集合,即未
k
标注模块集 C unkown 、训练集 C train 和测试集 C test .其中,C train 和 C test 是对已标注模块集的一种随机划分.
步骤 3. 构建、训练及测试语言模型.利用 C unkown 和 C train 集合内模块的代码数据和质量信息训练双向加权
语言模型 M 和 M 然后利用 C test 集合进行性能测试,其中,测试阶段不使用样本的标签信息.
,
*
*
步骤 4. 交叉熵及逆序交叉熵度量.为语言模型加载训练好的(准)最优参数 , 并分别利用 M 和 M 模型
度量 C train 和 C test 中软件模块的 M-CE 值和 M-CE-Inv 值,其中,熵值计算未使用模块的类标.
,
步骤 5. 软件模块度量.利用不同度量机制收集每个待测软件模块 S k 对应的一组度量元 例如规模度量、
k
内聚度量等,其中,已得到的 M-CE 值和 M-CE-Inv 值将作为新的度量元融入 中.
k
步骤 6. 构建并训练缺陷预测模型.首先利用软件模块的度量元及类标数据创建缺陷预测训练集 D train 和测
试集 D test .然后构建缺陷预测模型 F DP ,并使用 D train 数据训练模型 F DP .
*
步骤 7. 测试集预测及模型性能评估.使用训练好的模型 F 对测试集 D test 软件模块进行预测,然后依据结
DP
果评估模型的缺陷预测性能.
由上述过程可以看出,相比我们先前的工作 DefectLearner [48] (该方法未有效利用样本的质量标签数据,就缺陷
预测任务而言,语言模型的训练是无监督的),语言模型的训练与缺陷预测任务耦合得更加紧密,其中,语言模型利用
了部分缺陷预测样本的标签信息(保证测试集样本标签不可见),使得模型度量的修正代码 CE 值和逆序 CE 值更具
判别力.从而在面向缺陷预测任务时,这两种新度量元将较原有CE 度量元带来更大贡献.为便于分析,将方法的上述
运行过程划分为 3 个阶段:语料库学习阶段(阶段 I)、交叉熵度量阶段(阶段 II)和缺陷预测阶段(阶段 III),其中,阶段
I 涉及步骤 1~步骤 3,阶段 II 涉及步骤 2 和步骤 4,阶段 III 涉及步骤 1~步骤 2 及步骤 5~步骤 7.下面简述这 3 个阶
段的主要任务.