
Page 259 - 《软件学报》2021年第7期
P. 259
姜淑娟 等:基于路径分析和信息熵的错误定位方法 2177
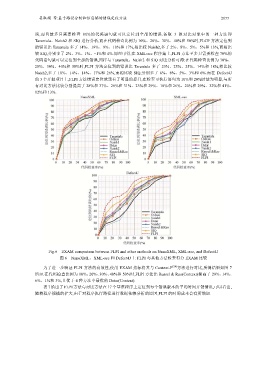
误,而且最多只需要检查 80%的代码语句就可以定位到全部的错误.各取 3 组对比对象中的一种方法即
Tarantula、Naish2 和 SIQ 进行分析,而在代码检查比例为 10%、20%、30%、40%和 50%时,FLCP 方法定位到
的错误比 Tarantula 多了 14%、19%、9%、10%和 17%,相比较 Naish2,多了 2%、8%、5%、5%和 13%,而相比
较 SIQ,分别多了 2%、3%、1%、1%和 4%.同理可得,在 XML-sec 程序集上,FLPI 方法至多只需要检查 70%的
代码语句就可以定位到全部的错误,同样与 Tarantula、Naish2 和 SIQ 对比分析可得:在代码检查比例为 10%、
20%、30%、40%和 50%时,FLPI 方法定位到的错误比 Tarantula 多了 23%、25%、25%、14%和 18%,相比较
Naish2,多了 10%、14%、14%、17%和 26%,而相比较 SIQ,分别多了 6%、8%、5%、3%和 6%.而在 Defect4J
的 3 个开源项目上,FLPI 方法错误定位效果有了明显的提升,在检查可执行语句为 10%和 20%时最为明显,与所
有对比方法比较分别提高了 28%和 37%、26%和 31%、23%和 29%、18%和 26%、20%和 29%、32%和 41%、
12%和 13%.
Fig.6 EXAM comparison between FLPI and other methods on NanoXML, XML-sec, and Defect4J
图 6 NanoXML、XML-sec 和 Defect4J 上 FLPI 与其他方法检查得分 EXAM 比较
为了进一步验证 FLPI 方法的有效性,使用 EXAM 指标将其与 Context-F [24] 方法进行对比,所得结果如图 7
所示.在代码检查比例为 10%、20%、30%、40%和 50%时,FLPI 方法比 Russel & Rao(Context)提高了 29%、14%、
6%、1%和 3%,且优于 4 种方法中最优的 Dstar(Context).
表 7 给出了 FLPI 方法与对比方法在 17 个基准程序上定位到每个错误版本的平均时间开销情况,可以看出,
随着程序规模的扩大,由于对程序执行路径进行数据依赖分析的原因,FLPI 的时间成本会有所增加.