
Page 243 - 《软件学报》2021年第7期
P. 243
牛长安 等:基于指针生成网络的代码注释自动生成模型 2161
表示权重越高,下方表示解码器在每个时刻的 p gen 值.因此可以看到,在生成 OOV 单词“bonk”时,解码器对输入
中的“bonk”的 Attention 权重最高,而输入序列中的其他单词几乎为 0,并且此时的 p gen 值几乎为 0,p gen 表示的是
解码器在两个模式间软切换中生成模式所占的比重,因此,此时的 p gen 表示模型倾向于完全切换到复制模式,又
因为此时输入序列中“bonk”的 Attention 权重接近 1,所以解码器直接复制输入序列中的“bonk”作为当前时刻的
输出.
本小节证明了指针生成网络可以减少生成注释中“UNK”的数量,提高注释的可读性,并且举例分析了作
用原理,从多方面证明了指针生成网络可以在一定程度上解决输出端的 OOV 问题.
3.4.4 RQ3:词库大小对模型性能的影响有什么规律?
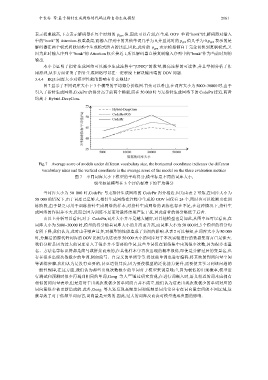
图 7 显示了不同词库大小下 3 个模型的平均得分折线图.首先可以看出,在词库大小为 5000~30000 时,由于
引入了指针生成网络,CodePtr 的得分高于前两个模型,而在 50 000 时与无指针生成网络下的 CodePtr 接近,两者
均高于 Hybrid-DeepCom.
Fig.7 Average score of models under different vocabulary size, the horizontal coordinate indicates the different
vocabulary sizes and the vertical coordinate is the average score of the model on the three evaluation metrics
图 7 不同词库大小下模型的平均得分,横坐标是不同的词库大小,
纵坐标是模型在 3 个评估标准下的平均得分
当词库大小为 50 000 时,CodePtr 与无指针生成网络的 CodePtr 得分相近.因为由表 2 可知,在词库大小为
50 000 的情况下,由于词库已足够大,指针生成网络在注释中生成的 OOV 词仅有 24 个,同时也可以推断出在训
练阶段,由于缺乏可用于训练指针生成网络的样本,对指针生成网络的训练也存在不足,在这种情况下,指针生
成网络的作用并不大,反而会因为训练不足而对最终结果产生干扰,因此前者的得分略低于后者.
由以上分析可以看出,对于 CodePtr,词库大小并不是越大越好,对其他模型也是如此,从图中还可以看出,在
词库大小为 5000~30000 时,模型的得分随着词库大小的升高而升高,而词库大小为 50 000 时,3 个模型的得分均
有所下降,我们认为,此时由于噪声过多,对模型的性能造成了负面的影响.从表 2 可以得知,在词库大小为 50 000
时,分解后的源代码词库的 OOV 比例为 0,这表示 50 000 大小的词库对于本次实验进行的数据集而言已足够大.
我们分析是因为过大的词库引入了很多并不需要的单词,这些单词仅在训练集中出现很少次数,因为很多变量
名、方法名等标识符都是简写或拼接而来的,在其他样本中再次出现的概率很低,即使是分解过后的变量名,也
存在很多出现次数极少的单词,例如简写、自定义的单词等等.将这些单词也进行编码,将其映射到词向量空间
等训练步骤,我们认为是没有必要的,甚至适得其反,因为要使模型的泛化能力提升,需要使其学习到该问题的
一般性规律,在这方面,我们认为那些出现次数极少的单词对于模型来说是噪声,因为极低的出现概率,模型进
行测试和预测时很少再遇到相同的单词,Gong 等人 [48] 通过研究发现,在进行词嵌入时,语义相近的词本应拥有
相似的词向量表示,但是这对于出现次数极少的单词而言并不成立,他们认为这是出现次数极少的单词对应的
词向量很少被更新造成的.此外,Gong 等人还发现高频单词和低频单词常常分布在词向量空间的不同区域,这
就导致了对于低频单词而言,词向量是无效的.因此,过大的词库反而会对模型造成负面的影响.