
Page 236 - 《软件学报》2020年第11期
P. 236
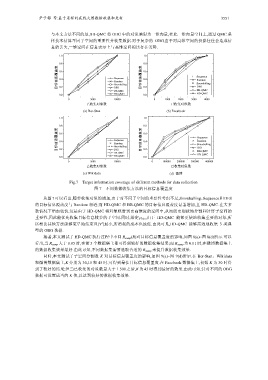
尹子都 等:基于采样的在线大图数据收集和更新 3551
与本文方法不同的是,BB-QMC 将 OBG 中的对象映射为一维向量,在此一维向量空间上,通过 QMC 采
样技术估算不同子空间的重要性并收集数据.对于复杂的 OBG,由于对高维空间的投影往往会造成信
息的丢失,一维空间在信息表示上与高维空间相比存在劣势.
1.0 1.0
0.8 0.8
目标信息覆盖度 0.6 Sequence 目标信息覆盖度 0.6 Sequence
0.4
0.4
Random
Random
Snowballing
Snowballing
0.2
DFS
BB-QMC
BB-QMC 0.2 DFS
0.0 HD-QMC 0.0 HD-QMC
0 5000 10000 0 1000 2000 3000 4000
已收集对象数 已收集对象数
(a) Ber-Stan (b) Facebook
1.0 1.0
0.8 0.8
目标信息覆盖度 0.6 Sequence 目标信息覆盖度 0.6 Sequence
Random
0.4
0.4
Random
Snowballing
Snowballing
0.2
DFS
BB-QMC
BB-QMC 0.2 DFS
HD-QMC
0.0 HD-QMC 0.0
0 5000 10000 0 100000 200000 300000 400000
已收集对象数 已收集对象数
(c) Wikidata (d) 微博
Fig.7 Target information coverage of different methods for data collection
图 7 不同数据收集方法的目标信息覆盖度
从图 7可以看出,随着收集对象的增加,由于对不同子空间的重要性考虑不足,Snowballing、Sequence和 DFS
的目标信息覆盖度与 Random 相近;而 HD-QMC 和 BB-QMC 的目标信息覆盖度显著增加,且 HD-QMC 在大多
数情况下增加较快.这是由于 HD-QMC 将对象映射到更高维度的空间中,从而能更细致地分割和计算子空间的
重要性,因此能优先收集目标信息较多的子空间.同时,给定ρ min ,由于 HD-QMC 能够更快地收集重要的对象,所
c
以相比其他方法能够更早地结束且|Ψ |最小,所消耗的成本也最低.由此可见,HD-QMC 能够高效地收集 3 类典
型的 OBG 数据.
接着,本文测试了 HD-QMC 执行过程中不同 R samp (R)对目标信息覆盖度的影响,如图 8(a)~图 8(d)所示.可以
看出,当 R samp 大于 0.05 时,在前 3 个数据集上都可得到较好的数据收集结果;而 R samp 为 0.01 时,在微博数据集上
的数据收集效果最好.由此可知,不同数据集需要选取合适的 R samp 来提升数据收集效果.
同时,本文测试了子空间分割数 K 对目标信息覆盖度的影响,如图 9(a)~图 9(d)所示.在 Ber-Stan、Wikidata
和微博数据集上,K 分别为 30,15 和 45 时,可得到最佳目标信息覆盖度.在 Facebook 数据集上,初始 K 为 30 时得
到了较好的结果;但当已收集的对象数量大于 1 500 之后,K 为 45 时得到最好的效果.由此可知,针对不同的 OBG
数据可设置适当的 K 值,以达到较好的数据收集效果.