
Page 186 - 《软件学报》2020年第11期
P. 186
3502 Journal of Software 软件学报 Vol.31, No.11, November 2020
验中剔除.
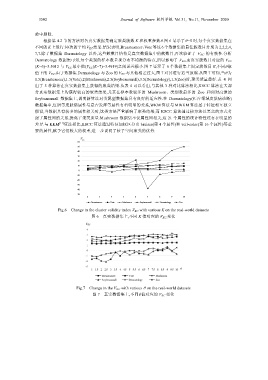
根据第 4.2 节的方法对各真实数据集确定聚类簇数 K 和权重参数θ.图 6 显示了θ=5 时,每个真实数据集在
不同的 K 上运行 30 次的平均 V KC 结果.结果表明,Breastcancer、Vote 等这 6 个数据集的最佳簇数目分别为 2,2,2,4,
7,7.除了数据集 Dermatology 以外,这些簇数目恰恰是真实数据集中的簇数目,再次验证了 V KC 的有效性.分析
Dermatology 数据集可知,每个类别的样本数呈现分布不均衡的特点,所以影响了 V KC ,而真实簇数目对应的 V KC
(K=6)=3.5012 与 V KC 最小值(V KC (K=7)=3.4919)之间误差极小.图 7 显示了 6 个数据集上固定簇数目 K,不同θ取
值下的 V KC .由于数据集 Dermatology 与 Zoo 的 V KC 与其他相差过大,图 7 对其进行适当放缩.从图 7 可知,当θ为
1.5(Breastcancer),1.5(Vote),2(Mushroom),2.5(Soybeansmall),3.5(Dermatology),1.5(Zoo)时,聚类质量最好.表 4 列
出了 5 种算法在真实数据集上获得的聚类结果.从表 4 可以看出,与其他 3 种对比算法相比,KSCC 算法在大部
分真实数据集上均获得较高的聚类结果,尤其在样本数较多的 Mushroom、类别数最多的 Zoo 和相对高维的
Soybeansmall 数据集上,说明新算法对类属型数据集具有良好的适应性.在 Dermatology(医疗领域皮肤病诊断)
数据集中,红斑等皮肤病属性与是否发痒等属性有着明显的关系,WKM 算法与 MWKM 算法基于特征相互独立
假设,当数据具有较多的属性相关时,这类方法严重影响了聚类结果;而 KSCC 算法通过核方法以黑盒的方式考
虑了属性间的关系,提高了聚类质量.Mushroom 数据集不仅属性间相关,这 21 个属性的统计特性还存在明显的
差异.与 KKM [11] 算法相比,KSCC 算法通过特征加权区分出 bruises(第 4 个属性)和 veil-color(第 16 个属性)等重
要的属性,赋予它们较大的权重,进一步说明了核子空间聚类的优势.
60
50
40
30
20
10
0
-10
-20
-30
-40
-50
2 3 4 5 6 7 8 9 10
Breastcancer Vote Mushroom Soybeansmall Dermatology Zoo
Fig.6 Change in the cluster validity index V KC with various K on the real-world datasets
图 6 真实数据集上,不同 K 值对应的 V KC 变化
V KC
θ
Fig.7 Change in the V KC with various θ on the real-world datasets
图 7 真实数据集上,不同θ值对应的 V KC 变化