
Page 38 - 《软件学报》2020年第9期
P. 38
张政馗 等:面向实时应用的深度学习研究综述 2659
向上取整,所以应该把 num_threads 设置成 32 的整数倍,否则会造成最后一个线程束中有部分线程被闲
置.CUDA 主程序启动后,会将操作指令和数据提供给线程块,线程块以锁步(lock-step)的方式广播到每个线程
束所占用的 SP 中;线程块一旦被调度到 GPU 的某个 SM,就必须从开始执行到结束.执行期间,线程束之间的数
据交换也由 CUDA 主程序负责管理.
GPU
Constant shared
memory across Global memory MMU
Global memory bus
Constant memory bus
SM0
Bus
More
SP0 SP1 SP2 SP3 SP4 SP5 SP6 SP7 SM1 SM2 SM3 SMn
Crossbar
0 1 2 3 4 5 6 7 8 9 A B C D E F
Shard memory
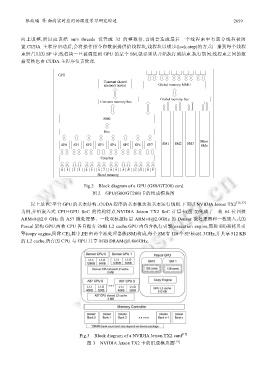
Fig.2 Block diagram of a GPU (G80/GT200) card
图 2 GPU(G80/GT200)卡的组成模块图
以上是 PC 平台 GPU 的基本结构、CUDA 程序的基本概念和基本运行规则.下面以 NVIDIA Jetson TX2 [15,37]
为例,介绍嵌入式 CPU+GPU SoC 的结构特点.NVIDIA Jetson TX2 SoC 计算卡(图 3)集成了一枚 64 位四核
ARMv8@2.0 GHz 的 A57 微处理器、一枚双核超标量 ARMv8@2.0GHz 的 Denver 微处理器和一枚嵌入式的
Pascal 架构 GPU.两枚 CPU 各自拥有 2MB L2 cache.GPU 内包含执行引擎(execution engine,简称 EE)和拷贝引
擎(copy engine,简称 CE),其中,EE 由两个流处理器簇(SM)构成,每个 SM 有 128 个 SP 核@1.3GHz,并共享 512 KB
的 L2 cache.所有的 CPU 与 GPU 共享 8GB DRAM@1.866GHz.
Fig.3 Block diagram of a NVIDIA Jetson TX2 card [15]
图 3 NVIDIA Jetson TX2 卡的组成模块图 [15]