
Page 264 - 《软件学报》2020年第9期
P. 264
祁磊 等:弱监督场景下的行人重识别研究综述 2885
当前,该领域的大部分工作都关注在有监督场景下的行人重识别问题.然而在现实中,行人重识别的数据标
注工作往往需要花费大量的人力和财力,特别是对跨摄像头间的行人数据进行关联的这一步骤.并且在当前深
度学习时代,大部分方法都是依赖大规模的有标记数据来训练一个深度模型.而数据标注的高成本使得有监督
的方法难以扩展到现实应用中,这也是阻碍行人重识别技术能够真正落地的一大因素.另一方面,在现实中我们
能够轻松获得大量无标记的行人数据.因此在行人重识别问题的研究中,如何使用少标记的大规模图像数据来
训练得到鲁棒的模型,具有重大的研究价值和意义.
目前,大部分行人重识别领域的工作主要集中在有监督场景下相关算法的研究.早些年,一些研究者主要致
力于提取鲁棒的特征来强化行人特征的判别性 [8−12] ,也有一些研究者主要关注在学习方法上,例如设计更好的
度量方法,以使其更容易地识别相同的人并区分不同的人 [13−16] ,或者通过学习公共的子空间或字典来消除不同
摄像头视角之间的差异 [17−19] .近些年,深度学习技术不断发展,特别是其在机器视觉应用领域取得了巨大成功,
新提出的行人重识别方法基本上都是基于深度学习的.其中,一些研究工作使用注意力机制的方式来提高行人
重识别模型的泛化能力 [20−28] ,也有一些研究工作通过设计损失函数来提升行人重识别模型的性能 [29−31] .最近也
出现了一些基于局部的学习方法 [32−35] ,该类方法虽然简单,但是可以获得更具有判别性的特征,在行人重识别任
务上取得了较优的性能.虽然在有监督场景下行人重识别问题已经有了突破性的进展,但是有监督场景下的学
习不利于行人重识别模型很好地泛化到其他场景下,因此考虑在深度学习需要大量的有标记数据参与训练的
背景下,研究弱监督场景下的少标记学习,在行人重识别任务中具有重大的意义与价值.
考虑到计算机视觉任务的相关应用在现实场景的落地需求,少标记学习在学术界和工业界渐渐受到关注.
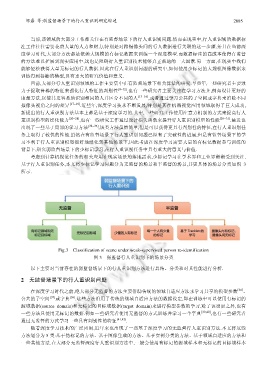
基于行人重识别任务,本文将少标记学习问题分为无监督的场景和半监督的场景,其更具体的场景分类如图 3
所示.
Fig.3 Classification of scene under weak-supervised person re-identification
图 3 弱监督行人重识别下的场景分类
以下主要对当前存在的弱监督场景下的行人重识别方法进行总结、分类和对其性能进行分析.
2 无监督场景下的行人重识别问题
在深度学习时代之前,绝大部分无监督的方法主要借助传统的领域自适应方法来学习共享的模型参数 [36] 、
公共的子空间 [37] 或字典 [38] .这些方法沿用了传统的领域自适应方法的数据设定,即在训练中可以使用有标记的
源域数据(source domain)和无标记的目标域数据(target domain)来进行模型参数的学习.除了该设定之外,也有
一些方法只使用无标记的数据.例如一些研究者使用无监督的方式训练并学习一个字典 [39,40] ,也有一些研究者
通过无监督的方式学习一些具有判别性的特征 [41,42] .
随着深度学习技术的广泛应用,近年来也出现了一些基于深度学习的无监督行人重识别方法.本文将这些
方法划分为 5 类:基于伪标记的方法、基于图像生成的方法、基于实例分类的方法、基于领域自适应的方法和
一些其他方法.在大部分无监督深度行人重识别方法中,一般会使用有标记的源域样本和无标记的目标域样本