
Page 236 - 《软件学报》2020年第12期
P. 236
3902 Journal of Software 软件学报 Vol.31, No.12, December 2020
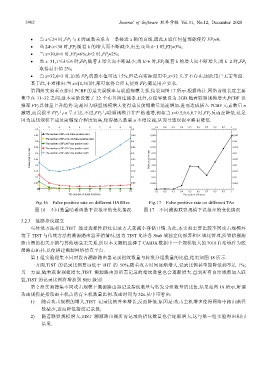
• 当 x≤24 时,FP f 与 k 的函数关系为一条接近 x 轴的直线,因此,k 取任何值都能使得 FP f ≈0;
• 当 24<x<30 时,FP f 随着 k 的增大而不断减少,直至 0;当 k=1 时,FP f ≈3%;
• 当 x=30,k=1 时,FP f ≈6%;k=2 时,FP f ≈2%;
• 当 x=31,1≤k≤6 时,FP f 随着 k 增大而不断减小;当 k>6 时,FP f 随着 k 的增大而不断增大;当 k=2 时,FP f
取得最小值 2%;
• 当 x=32,k=3 时,虽然 FP f 的最小值可达 15%,但是在实际应用中,x=32 几乎不存在,因此用户无需考虑.
基于此,不难推出:当 x∈[1,31]时,都可取得合理 k,使得 FP f 满足用户要求.
第四组实验重点探讨 PCBF 的最大误报率与联盟规模关系,结果如图 17 所示.根据统计,网络前缀长度主要
集中在 11~32 之间,故本实验设置了 22 个布鲁姆过滤器.此外,存储容量设为 2GB.随着联盟规模增大,PCBF 误
报率 FP f 总体呈上升趋势.这是因为联盟规模增大使得成员前缀数量迅速增加,进而造成插入 PCBF 元素数量 n
激增,而误报率 FP f 与 n 呈正比.不过,FP f 与联盟规模并非严格递增,例如当 x=0.5,0.6,0.7 时,FP f 反而在降低.这是
因为这些规模下成员前缀聚合程度较高,使得插入数量 n 不增反减,从而导致误报率略有降低.
1 2 3 4 5 6 7 8 9 10 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1
0.5 0.5 0.05 0.05
The number of BF<=24-False positive rate1
0.45 0.45 0.045 0.045
The number of BF>24&<30-False positive rate2
0.4 0.4 0.04 0.04
The number of BF=30-False positive rate3
0.35 The number of BF=31-False positive rate4 0.35 0.035 0.035
False positive rate 0.25 The number of BF=32-False positive rate5 0.3 False positive rate 0.025 0.03
0.03
0.3
0.025
0.25
0.02
0.2
0.15 0.2 0.015 0.02
0.015
0.15
0.1 0.1 0.01 0.01
0.05 0.05 0.005 0.005
0 0 0 0
1 2 3 4 5 6 7 8 9 10 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1
The number of hash functions The scale of alliances
Fig.16 False positive rate on different HASHes Fig.17 False positive rate on different TAs
图 16 不同数量哈希函数下误报率的变化情况 图 17 不同溯源联盟规模下误报率的变化情况
3.2.3 链路指纹建立
与传统方法相比,TIST 通过选择性指纹记录方式来减小存储开销.为此,本实验主要比较不同攻击规模环
境下 TIST 与传统方法的溯源路由器开销情况.因为 TIST 允许各 Stub 域独立化部署和区域化管理,所管辖溯源
路由器的相关开销与其他域毫无关系,所以本文随机选择了 CAIDA 数据中一个规模较大的 7018 自治域作为底
层路由拓扑,以便搭建溯源网络仿真平台.
第 1 组实验搜集不同时段内溯源路由器记录指纹数量与转发分组数量的比值,结果如图 18 所示.
一方面,TIST 的记录比例要远低于 HIT 的 50%,随着攻击时间逐渐增大,记录比例甚至能降低到不足 1%;
另一方面,随着联盟规模增大,TIST 溯源路由器所需记录的指纹数量也会逐渐增大.直到所有自治域都加入联
盟,TIST 的记录比例将增加到 SEE 级别.
第 2 组实验搜集不同攻击规模下溯源路由器记录指纹数量与转发分组数量的比值,结果如图 19 所示.所谓
攻击规模是指攻击主机占所有主机数量比例.攻击时间为 32s.从中可看出:
1) 随着攻击规模的增大,TIST 记录比例并未增长,反而降低.原因是:攻击主机增多使得网络中路由路径
数减少,进而降低指纹记录数;
2) 随着联盟规模增大,TIST 溯源路由器所需记录的指纹数量也会逐渐增大,这与第一组实验得出相同
结果.