
Page 251 - 《软件学报》2020年第10期
P. 251
张伟 等:一种时间序列鉴别性特征字典构建算法 3227
正则化的逻辑回归模型对转换后的实例进行分类 [29] .此外,本文还利用逻辑回归学习到的权重对特征字典进
行分析.
3 实验分析
本节对我们所提模型的相关实验内容进行详细介绍.主要包括 4 个方面:模型参数分析、模型设计的方法
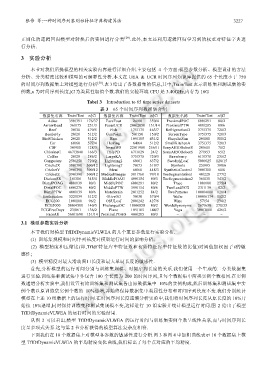
分析、分类精度比较和模型的可解释性分析.本文在 UEA & UCR 时间序列知识库提供的 65 个长度小于 750
的时间序列数据集上对模型进行分析 [30] .表 3 给出了各数据集的信息,其中,Train/Test 表示训练集和测试集的实
例数,n 为时间序列长度,|C|为类属性取值个数.我们的实验环境 CPU 是 3.40GHz,内存为 16G.
Tabel 3 Introduction to 65 time series datasets
表 3 65 个时间序列数据集介绍
数据集名称 Train/Test n/|C| 数据集名称 Train/Test n/|C| 数据集名称 Train/Test n/|C|
Adiac 390/391 176/37 FaceFour 24/88 350/4 ProximalPOC 600/291 80/2
ArrowHead 36/175 251/3 FacesUCR 200/2050 131/14 ProximalPTW 400/205 80/6
Beef 30/30 470/5 Fish 175/175 463/7 RefrigerationD 375/375 720/3
BeetleFly 20/20 512/2 GunPoint 50/150 150/2 ScreenType 375/375 720/3
BirdChicken 20/20 512/2 Ham 109/105 431/2 ShapeletSim 20/180 500/2
Car 60/60 577/4 Herring 64/64 512/2 SmallKitchenA 375/375 720/3
CBF 30/900 128/3 InsectWS 220/1980 256/11 SonyAIBORobotS 20/601 70/2
ChlorineC 467/3840 166/3 ItalyPD 67/1029 24/2 SonyAIBORobotS 27/953 65/2
Coffee 28/28 286/2 LargeKA 375/375 720/3 Strawberry 613/370 235/2
Computers 250/250 720/2 Lightning2 60/61 637/2 SwedishLeaf 500/625 128/15
CricketX 390/390 300/12 Lightning7 70/73 319/7 Symbols 25/995 398/6
CricketY 390/390 300/12 Meat 60/60 448/3 SyntheticControl 300/300 60/6
CricketZ 390/390 300/12 MedicalImages 381/760 99/10 ToeSegmentation1 40/228 277/2
DiatomSR 16/306 345/4 MiddlePOAG 400/154 80/3 ToeSegmentation2 36/130 343/2
DistalPOAG 400/139 80/3 MiddlePOC 600/291 80/2 Trace 100/100 275/4
DistalPOC 600/276 80/2 MiddlePTW 399/154 80/6 TwoLeadECG 23/1139 82/2
DistalPTW 400/139 80/6 MoteStrain 20/1252 84/2 TwoPatterns 1000/4000 128/4
Earthquakes 322/139 512/2 OliveOil 30/30 570/4 Wafer 1000/6174 152/2
ECG200 100/100 96/2 OSULeaf 200/242 427/6 Wine 57/54 234/2
ECG5000 500/4500 140/5 PhalangesOC 1800/858 80/2 WordsSynonyms 267/638 270/25
ECGFiveDays 23/861 136/2 Plane 105/105 144/7 Yoga 300/3000 426/2
FaceAll 560/1690 131/14 ProximalPOAG 400/205 80/3 − − −
3.1 模型参数实验分析
本节我们对模型 TfIDfDynamicVLWEA 的几个重要参数进行实验分析.
(1) 训练集规模和时间序列长度对模型运行时间的影响分析;
(2) 模型精度和压缩比(即,TfIdf 特征库中特征数和初始特征库中特征数的比值)对阈值加权因子θ的敏
感性;
(3) 模型精度对最大滑动窗口长度和最大单词长度的敏感性.
首先,分析模型的运行时间分别与训练集规模、时间序列长度的关系.我们使用一个生成的二分类数据集
进行实验.训练集和测试集中各包含 100 个长度为 200 的时间序列,且每个数据集中两类实例个数相同.在实例
数递增分析实验中,我们设置初始训练集和测试集各由原数据集中 10%的实例构成,然后训练集和测试集中实
例个数以原训练集实例个数的 10%递增,并始终保持数据集中类属性分布和时间序列长度不变.我们分别统计
模型在上述 10 组数据上的运行时间.在时间序列长度递增分析实验中,我们将时间序列长度从原长度的 10%开
始按 10%递增,同时保持训练集和测试集规模不变,这样进行 10 组实验并统计模型运行时间.图 2 给出了模型
TfIDfDynamicVLWEA 的运行时间的实验结果.
从图 2 可以看出,模型 TfIDfDynamicVLWEA 的运行时间与训练集实例个数呈线性关系,而与时间序列长
度呈多项式关系.这与第 2 节分析获得的模型算法复杂度相符.
下面我们在 10 个数据集上对模型各参数的敏感性进行分析.图 3 和图 4 中加粗曲线表示 10 个数据集上模
型 TfIDfDynamicVLWEA 的平均精度变化曲线,我们标出了每个点对应的平均精度.