
Page 234 - 《软件学报》2020年第10期
P. 234
3210 Journal of Software 软件学报 Vol.31, No.10, October 2020
节点中所有对象在对应关键字的最大权重.因此,虚拟四分树的非叶子节点的关键字最大权重需要从该节点下
的所有叶子节点获得,导致线性四分树的重复访问,影响了查询效率.相比之下,在空间方面,VGird 算法中通过二
进制的位运算(见公式(5))直接获得附近单元位置,利用 visit 布尔数组防止了单元的重复访问;在文本关键字方
面,VGird 直接运用的是聚集线性四分树中存储的每个关键字的最大权重.因此,查询效率得到了明显提高.
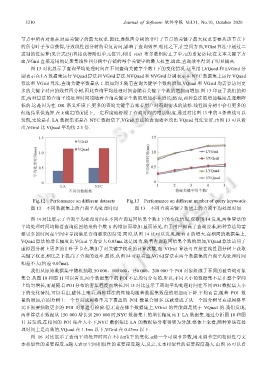
图 13 对比展示了查询平均处理时间在不同查询关键字个数 l 下的变化情况.这里用 LVQuad 和 LVGrid 分
别表示在 LA 数据集运行 VQuad 算法和 VGrid 算法.NVQuad 和 NVGrid 分别表示在 NYC 数据集上运行 VQuad
算法和 VGrid 算法.查询关键字数量从 1 增加到 5.随着查询关键字个数的增加,VQuad 和 VGrid 均需要访问更
多的关键字对应的线性四分树,因此查询平均处理时间会随着关键字个数的增加而增加.图 13 印证了我们的想
法,两种算法的查询平均处理时间均随着查询关键字个数的增加亦在增长.然而,两种算法的增加幅度是逐渐降
低的.这是因为在 OR 语义环境下,更多的查询关键字意味着用户对查询需求的放松.线性四分树中会有更多的
候选结果供选择.在 k 确定的前提下,一定程度地舒缓了查询时间的增长幅度.通过对比图 13 中的 4 条曲线可以
发现,无论是在 LA 数据集还是在 NYC 数据集下,VGrid 算法的查询效率均比 VQuad 算法要好,由图 13 可以看
出,VGrid 比 VQuad 平均快 2.5 倍.
Fig.12 Performance on different datasets Fig.13 Performance on different number of query keywords
图 12 不同数据集上的查询平均处理时间 图 13 不同查询关键字数量上的查询平均处理时间
图 14 对比展示了查询平均处理时间在不同查询返回结果个数 k 下的变化情况.观察图 14 发现,两种算法的
平均处理时间均随着查询返回结果的个数 k 的增加而增加.显而易见,由于用户提高了查询要求,两种算法均需
要更多的时间在空间中寻找满足查询要求的结果.同时,从图 14 还可以发现,随着 k 的增大,在相同的数据集上,
VQuad 算法的增长幅度比 VGrid 平均要大 0.05ms.这是因为,随着查询返回结果个数的增加,VQuad 算法访问了
虚拟四分树上更多的非叶子节点,增加了对关键字权重的计算次数,而 VGrid 算法可直接在线性四分树上获取
关键字权重,相比之下提高了查询的效率.最终,从图 14 可以看出,VGrid 算法在两个数据集的查询平均处理时间
相差不大(约差 0.07ms).
我们从原始数据集中随机抽取 50 000、100 000、150 000、200 000 个 POI 对象组成了不同的被查询对象
集合.从图 10 和图 11 可以看出,两个数据集中的 POI 不是均匀分布的.所以,不同大小的数据集不是在整个空间
上均匀增长,而是随着 POI 分布的密集程度而增长.图 15 对比显示了查询平均处理时间在不同 POI 数据集大小
下的变化情况.可以看出,整体上来看,两种算法的性能均随着数据集数量的增加而下降.平均而言,随着 POI 数
量的增加,在四分树上一个节点或网格单元下覆盖的 POI 数量会增多.这就造成了从一个四分树节点或网格单
元下需要抽取更多的 POI 对象进行检验.但无论在哪个数据集上,VGrid 的性能都是优于 VQuad 的.我们发现,
两种算法在数据从 150 000 增长到 200 000 时,NYC 数据集上的增长幅度高于 LA 数据集.通过分析图 10 和图
11 后发现,在相同的 POI 集合大小下,NYC 数据集比 LA 的数据集分布得更为分散.整体上来看,两种算法在处
理时间上是高效的,VQuad 在 1.1ms 以下,VGrid 在 0.43ms 以下.
图 16 对比展示了查询平均处理时间在不同α值下的变化.α是一个可调节参数,用来调节空间相似性与文
本相似性的重要程度.α越大表示空间相似性的重要程度越大,反之,文本相似性的重要程度越大.由图 16 可以看