
Page 216 - 《软件学报》2020年第10期
P. 216
3192 Journal of Software 软件学报 Vol.31, No.10, October 2020
4.4 双缓冲优化
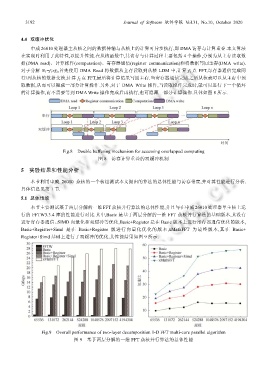
申威 26010 处理器主从核之间的数据传输与从核上的计算可异步执行,即 DMA 访存与计算重叠.本文算法
在实现时利用了此特性,以提升性能.在从核函数中,其访存与计算过程主要包括 4 个操作,分别为从主存读取数
据(DMA read)、计算操作(computation)、寄存器通信(register communication)和将数据写回主存(DMA write).
对于分解 N 1 =f 1 ×f 2 ,首先使用 DMA Read 将数据从主存读取到从核 LDM 中,计算 f 1 点 FFT,寄存器通信完成同
行/列从核的数据交换,计算 f 2 点 FFT,最后将计算结果写回主存.当寄存器通信完成之后从核就可以从主存中预
取数据,从而可以隐藏一部分计算操作.另外,对于 DMA Write 操作,当读取操作完成时,就可以进行下一个循环
的计算操作,而不需要等到 DMA Write 操作完成后再执行,也可隐藏一部分计算操作.具体如图 8 所示.
Fig.8 Double buffering mechanism for accessing overlapped computing
图 8 访存计算重叠的双缓冲机制
5 实验结果和性能分析
本节利用申威 26010 众核的一个核组测试本文提出的算法的总体性能与访存带宽,并对其性能进行分析.
具体信息见第 1 节.
5.1 总体性能
本节主要测试基于两层分解的一维 FFT 众核并行算法的总体性能,并且与在申威 26010 处理器单主核上运
行的 FFTW3.3.4 库的性能进行对比.其中,Basic 是基于两层分解的一维 FFT 众核并行算法的基础版本,其没有
进行寄存器通信、 SIMD 向量化和双缓冲等优化,Basic+Register 是在 Basic 版本上进行寄存器通信优化的版本,
Basic+Register+Simd 是在 Basic+Register 版进行向量化优化的版本,xMathFFT 为最终版本,其在 Basic+
Register+Simd 基础上进行了双缓冲的优化,其性能结果如图 9 所示.
Fig.9 Overall performance of two-layer decomposition 1-D FFT multi-core parallel algorithm
图 9 基于两层分解的一维 FFT 众核并行算法的总体性能