
Page 215 - 《软件学报》2020年第10期
P. 215
赵玉文 等:申威 26010 众核处理器上一维 FFT 实现与优化 3191
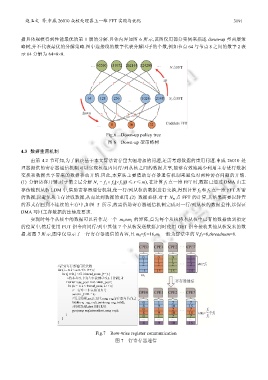
据具体规模得到性能最优的第 1 层的分解.具体内容如图 6 所示,该图仅用部分实例来描述 down-up 型两层策
略树,并不代表最优的分解策略.图中连接线的数字代表分解因子的个数,例如节点 64 与节点 8 之间的数字 2 表
示 64 分解为 64=8×8.
Fig.6 Down-up policy tree
图 6 Down-up 型策略树
4.3 数据重用机制
由第 4.2 节可知,为了解决基于本文算法访存量大幅增加的问题,还需考虑数据的重用问题.申威 26010 处
理器提供的寄存器通信机制可以实现核组内同行/列从核之间的数据共享,能够有效地减少利用主存进行数据
交换和数据共享带来的数据移动开销.因此,本算法主要借助寄存器通信机制来避免对两种访存问题的开销.
(1) 分解访存开销.对于第 2 层分解 N = r f × 1 f 2 [ f× 3 ](1≤≤ m ), 在计算 f 1 点一维 FFT 时,数据已通过 DMA 由主
r
存传输到从核 LDM 中,借助寄存器通信机制,使一行/列从核的数据进行交换,得到计算 f 2 和 f 3 点一维 FFT 所需
的数据,以避免从主存读取数据,从而达到数据的重用.(2) 数据重排.对于 N m 点 FFT 的计算,其结果需要以转置
的形式存回到不连续的主存中,如图 5 所示,故需借助寄存器通信机制完成对一行/列从核的数据重排,以保证
DMA 写回主存数据的连续度要求.
实现时每个从核中的数据可以看作是一个 m 0 ×m 1 的矩阵,首先每个从核将本从核中已有的数据放到指定
的位置中,然后使用 PUT 指令向同行/列中其他 7 个从核发送数据,同时使用 GET 指令接收其他从核发来的数
据.如图 7 所示,图中仅显示了一行寄存器通信的内容,且 m 0 =f 1 =16,m 1 一般为算法中的 V,f 2 =8,threadnum=8.
Fig.7 Row-wise register communication
图 7 行寄存器通信