
Page 135 - 《软件学报》2020年第10期
P. 135
王康瑾 等:在离线混部作业调度与资源管理技术研究综述 3111
的资源以减少性能干扰,防止在线作业的性能持续受到影响.解决干扰的相关研究有:
文献[12]中 CPI2 通过数据分析发现了在线作业 CPI 和在线作业 RT 的相关性,因此可以使用硬件级别的指
标 CPI 作为性能指标,通过监控和检测 CPI 的波动判断作业是否被干扰,检测到干扰后使用干扰模型识别干扰
者,最后使用限制干扰者 CPU 或者杀死干扰者解决干扰.该方法的局限性在于:(1) 整个系统的运行效率依赖于
干扰模型对于干扰者的识别准确率;(2) 仅限制干扰者的 CPU 资源而忽略了其他共享资源会导致无法有效地
找到干扰源,因此无法准确、有效地处理其他资源上的性能干扰问题.
文献[36]提出了资源管理框架 DeepDive,通过监控底层的性能指标(如 CPI)预测 VM 之间的性能干扰,并识
别造成干扰的 VM,随后采用迁移的方法将干扰者迁移到其他节点.实验证明了 DeepDive 中的干扰预测准确率
高达 90%以上.但是 DeepDive 针对干扰采取虚拟机迁移的技术可能会使某些资源竞争较高的容器被反复迁移,
考虑到迁移容器的开销相对较高,反复迁移可能会引起系统抖动.
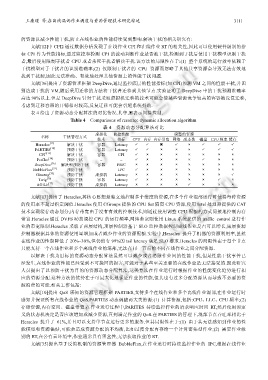
表 4 给出了资源动态分配算法的对比情况.其中,表示间接控制.
Table 4 Comparisons of resource dynamic allocation algorithm
表 4 资源动态分配算法对比
虚拟化 监控性能 调整的资源
名称 干扰管理方式
技术 指标 CPU 内存 内存带宽 网络 副本数 磁盘 CPU 频率 缓存
Heracles [13] 解决干扰 容器 Latency 3 3 3 2 3 3 3
PARTIES [10] 预防干扰 容器 Latency 3 3 2 2 2 3 3 3
CPI 2[12] 解决干扰 容器 CPI 3 2 2 2 2 2 2 2
PerfIso [74] 预防干扰 − − 3 2 2 2 2 3 2 2
DeepDive [36] 解决和预防干扰 容器 PMC 2 2 2 2 2 2 2 2
BubbleFlux [35] 预防干扰 − IPC 3 2 2 2 2 2 2 2
Ginseng [75] 预防干扰 虚拟机 Latency 2 2 2 2 2 2 2 3
Twig [76] 预防干扰 容器 Latency 3 2 2 2 2 2 3 2
AGILE [77] 预防干扰 虚拟机 Latency 2 2 2 2 3 2 2 2
文献[13]提出了 Heracles,其核心思想是独立地控制多个维度的资源,在多个作业混部运行时使得每种资源
的使用率不超过指定阈值.Heracles 使用 CGroups 提供的 CPU Set 隔离 CPU 资源,使用 Intel 处理器提供的 CAT
技术实现缓存动态划分,内存带宽由于没有有效的控制技术,则通过使用调整 CPU 配额的方式间接地控制内存
带宽.Heracles 通过 DVFS 动态调控 CPU 的运行频率,网络带宽则使用 Linux 系统提供的 traffic control 进行作
业的带宽限制.Heracles 采取了两层结构,顶层控制器基于 SLO 监控数据控制离线作业是否可以增长,底层资源
控制器根据具体的资源使用量增加或者减少作业的资源配额.实验中,Heracles 提升了机器的资源利用率,虽然
在线作业的性能降低了 20%~30%,但仍然有 99%的 tail latency 满足 SLO 要求.Heracles 的局限性在于每个节点
只能支持一个在线作业和多个离线作业的混部,无法在同一节点的不同在线作业之间分配资源.
以解决干扰为目标的资源动态分配算法虽然可以减少或者消除作业间的性能干扰,但是性能干扰事件已
经发生,在线作业的性能已经受到不可挽回的损害,可能对于某些至关重要的在线作业是无法接受的.因此研究
人员提出了以预防干扰为目的的资源动态分配算法,这类算法在作业运行时根据作业的性能变化趋势进行相
应的资源分配.这种方法的优势在于可最大化地保证作业的性能,但其也有过多分配资源从而导致不必要的资
源浪费的可能.相关工作包括:
文献[10]提出 QoS 感知的资源管理框架 PARTIES,支持多个在线作业和多个离线作业混部,在作业运行时
感知并保证所有在线作业的 QoS.PARTIES 动态调整两大类资源:(1) 计算资源,包括:CPU、LLC、CPU 频率;(2)
存储资源,内存空间、磁盘带宽.在作业运行过程中,PARITES 持续监控作业的请求响应时间 RT,然后使用预定
义的状态机决定是否应该增加或减少资源,直到满足作业的 QoS.在 PARTIES 的管理下,混部节点吞吐率相比于
Heracles 提升了 61%,并且可以支持单节点运行更多的服务.但其局限性在于:(1) 由于其无法感知到作业的性
能模型和资源偏好,可能会造成资源分配的不均衡,比如过度分配内存给一个计算密集型作业;(2) 需要作业级
别的 RT,在公有云环境中,作业通常具有黑盒性,无法获取作业的 RT.
文献[35]提出基于反馈机制的资源管理器 BubbleFlux,在作业运行时持续监控作业的 IPC,根据在线作业