
Page 242 - 《水产学报》2026年第3期
P. 242
3 期 李坤达,等:基于改进 YOLOv11 的海洋牧场中鲍的检测方法 50 卷
20 mm 1 42 mm 2 30 mm 3
30 mm 40 mm 40 mm
4 5 6
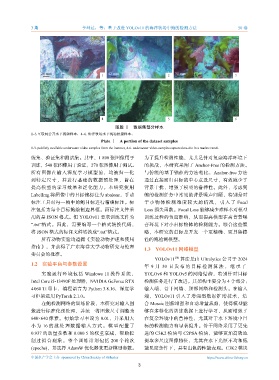
图版 Ⅰ 数据集部分样本
1~3.互联网公开水下视频样本,4~6. 海洋牧场水下现场拍摄样本。
Plate Ⅰ A portion of the dataset samples
1-3. publicly available underwater video samples from the internet, 4-6. underwater video samples captured on-site in a marine ranch.
练集、验证集和测试集。其中,1 890 张图像用于 为了提升检测性能,尤其是针对复杂海洋环境下
训练,540 张图像用于验证,270 张图像用于测试。 的挑战,本研究采用了 Anchor-Free 的检测方法。
所有图像在输入深度学习模型前,均被归一化 与传统的基于锚框的方法相比,Anchor-free 方法
到特定尺寸,并进行基础的数据预处理,旨在 通过直接回归目标的中心点及尺寸,有效减少了
提高模型的学习效果和泛化能力。本研究使用 背景干扰,增强了模型的鲁棒性。此外,考虑到
LabelImg 将图像中的目标鲍标注为 abalone,手动 鲍的检测任务中常见的背景噪声问题,特别是对
标注工具对每一帧中的鲍目标进行精确标注。标 于 小 物 体 检 测 难 度 较 大 的 情 况 , 引 入 了 Focal
注包括为每个目标鲍绘制边界框。而标注文件采 Loss 损失函数。Focal Loss 能够减少难样本对模型
用的是 JSON 格式。但 YOLOv11 要求训练文件为 训练过程的负面影响,从而提高模型在高背景噪
“.txt”格式。因此,需要编写一个格式转换代码, 音环境下对小目标物体的检测能力。综合这些策
将 JSON 格式的标注文件转换成“.txt”格式。 略,本研究的目标是开发一个更精确、更具鲁棒
所有动物实验均遵循《实验动物护理和使用 性的鲍检测模型。
指南》,并获得了广东海洋大学动物研究与伦理
1.3 YOLOv11 网络模型
委员会的批准。
YOLOv11 [30] 算法是由 Ultralytics 公司于 2024
1.2 实验平台与参数设置
年 9 月 30 日 发 布 的 目 标 检 测 算 法 , 继 承 了
实验运行环境包括 Windows 11 操作系统, YOLOv8 和 YOLOv5 的网络结构,特别针对目标
Intel Core i5-13490F 处理器,NVIDIA GeForce RTX 检测任务进行了改进。其架构主要分为 4 个部分:
4 060 Ti 显卡,编程语言为 Python 3.8.16,深度学 输入端、骨干网络、颈部网络和检测头。在输入
习框架选用 PyTorch 2.1.0。 端,YOLOv11 引入了增强型数据扩增技术,结
在鲍检测网络的训练阶段,本研究对输入图 合 Mosaic 图像增强和自动增量裁剪,使得模型能
像进行标准化预处理,并统一将图像尺寸调整为 够在多样化的训练数据上进行学习,从而增强了
640×640 像素。初始学习率设为 0.01,并采用大 在复杂环境中的鲁棒性,尤其对于水下环境中目
小 为 16 的 批 处 理 数 据 输 入 方 式 。 模 型 配 置 了 标的检测能力有显著提升。骨干网络采用了更先
0.937 的动量参数和 0.000 5 的权重衰减,帮助控 进的 C3K2 模块与 C2PSA 模块,能够更加高效地
制过拟合现象。整个训练计划包括 200 个轮次 提取多尺度图像特征,尤其在水下光照不均和低
(epochs),并选择 AdamW 优化器来更新模型参数。 能见度条件下,具有出色的性能表现。C3K2 模块
中国水产学会主办 sponsored by China Society of Fisheries https://www.china-fishery.cn
3