
Page 87 - 《软件学报》2025年第12期
P. 87
5468 软件学报 2025 年第 36 卷第 12 期
图像进行预处理, 包括灰度化、二值化、去噪等操作, 以提高后续处理的准确性和效率. 文本定位阶段识别出图像
中可能存在的文本区域, 本方法中采用了 Canny 边缘检测的方法. 在文本分割阶段, 采用垂直投影法, 根据投影值
分割字符, 得到单个字符或单词的图像. 特征提取阶段, 通过提取图像中字符的特征, 如形状、轮廓、像素分布等,
将图像数据转换成可用于分类的向量形式. 在分类识别阶段, 利用机器学习算法或深度学习模型对提取的特征进
行分类识别, 将字符映射成相应的文字.
基于以上介绍, 结合本方法实际需求, 主要对录制控件、回放页面进行 OCR 技术处理, 完成文字匹配和处理
的工作. 对于回放界面, OCR 技术不仅保存识别出的文字文本, 还将保存文本所在的位置.
4.3.2 语义匹配
OCR 技术能够对字符串进行严格的匹配. 但是, 由于不同的开发团队以及不同的平台可能会对同一个控件做
措辞不同但语义相同的展示. 在文本匹配阶段本方法还使用了基于 Sentence Transformers 框架的 sbert-base-
chinese-nli 预训练模型进行语义匹配, 可用于包括中文和英文在内的 13 种语言.
Sentence Transformers 是一个用于生成文本向量表示的 Python 框架, 其主要目的是将句子或段落转换为高维
向量空间中的向量, 从而支持各种自然语言处理任务. 该框架建立在 Hugging Face 的 Transformers 库之上, 通过使
用预训练的 Transformer 模型, 可以将文本输入映射到具有语义丰富表示的向量空间中. 这些模型在大规模语料库
上进行了无监督训练, 学习了丰富的语义信息. 通过微调这些预训练模型, Sentence Transformers 能够根据具体任
务和数据集的特点, 生成适用于不同应用场景的文本向量表示.
OCR 技术可以帮助实现严格的文本匹配. 而语义模型匹配则可用来实现字词不同、但语义相同的文本匹配.
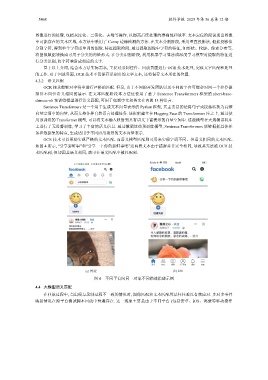
如图 4 所示, “分享新鲜事”和“分享一下你的新鲜事吧”这两段文本由于措辞并非完全相同, 导致其无法被 OCR 技
术匹配到, 但却因其语义相同, 故可在语义匹配中被匹配到.
(a) 鸿蒙 (b) iOS
图 4 不同平台间同一对象不同描述措辞示例
4.4 大模型语义匹配
在回放过程中, 当出现与录制过程不一致的情况时, 图像匹配和文本匹配算法往往难以有效应对. 多对多事件
映射情况在跨平台测试脚本回放中普遍存在. 这一现象主要是由于不同平台 (包括安卓、iOS、鸿蒙等移动操作