
Page 477 - 《软件学报》2025年第12期
P. 477
5858 软件学报 2025 年第 36 卷第 12 期
− →
− →
− →
− →
p c ( v i,j ∩ v k,l ) ⩾ p c ( v i,j )· p c ( v k,l ) (7)
− → − → − → − → − → − →
˜ p c ( v i,j ∪ v k,l ) ⩽ p c ( v i,j )+ p c ( v k,l )− p c ( v i,j ∩ v k,l ) (8)
虽然得到了联合修改概率上限, 但是邻近像素的正相关性随着距离变近而增强, 简单的假设所有邻近像素相
互独立, 距离越近计算出的联合修正概率偏差越大. 因此, 在假定像素相互独立时, 本文要求邻近像素与给定像素
的距离尽可能相近, 比如在一个 3×3 的邻域中, 所有像素到中心像素的距离是相同的, 这样可以保证相关性的一致
性, 同时所有邻域像素联合修正概率偏差较为一致, 在筛选最大熵的类别联合修正概率较为准确.
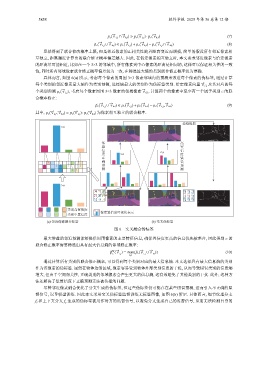
具体而言, 如图 6(a) 所示, 考虑每个像素的周围 3×3 像素邻域内的预测来改进每个像素的伪标签, 通过计算
− →
每个类别的邻近像素最大熵作为类别预测, 选择熵最大的类别作为伪标签类别. 给定像素向量 v i.j 及其对应的每
p c ( v i.j ), 考虑每个像素周围 3×3 − → c 的联
v k.l , 计算两个的像素中至少有一个属于类别
− →
个类别预测 像素的邻域像素
合概率修正:
− →
− →
− → −→
− →
− →
˜ p c ( v i,j ∪ v k.l ) ⩽ p c ( v i,j )+ p c ( v k.l )− p c ( v i,j , v k.l ) (9)
− →
− →
− → −→
其中, p c ( v i,j , v k,l ) = p c ( v i,j )· p c ( v k,l ) 为像素相互独立的联合概率.
边缘提取
>α
低 高
置 置
信 <α 信
度 >α 度
正 错
确 误
预 预
测 测
>α
类别高置信度
类别中置信度 像素置信度可视化表示
(a) 邻近像素融合标签 (b) 交叉伪标签
图 6 交叉融合伪标签
最大增益的邻近预测能够提供周围像素的主要特征信息, 确保置信度更高的信息优先被整合, 因此类别 c 的
联合修正概率需要筛选出具有最大信息熵的邻域修正概率:
− →
− →
M −→
˜ p ( v ) = max( ˜p c ( v ∪ v )) (10)
c i,j i,j k,l
k,l
通过计算所有类别的联合修正概率, 可以得到每个类别对应的最大信息熵. 本文选择具有最大信息熵的类别
作为该像素的伪标签. 虽然在物体边缘区域, 像素容易受到物体外部类别信息的干扰, 从而导致错误类别的信息熵
增大, 但由于空间相关性, 正确类别的邻域像素会产生更大的信息熵, 这有效避免了其他类别的干扰. 此外, 这种方
法还解决了低置信度下正确预测无法被传播的问题.
尽管邻近像素融合优化了分支生成的伪标签, 但这些伪标签仍可能存在某些错误预测, 进而引入不正确的监
督信号, 误导模型训练. 因此本文采用交叉伪标签监督训练无标签图像, 如图 6(b) 所示. 具体而言, 细节纹理分支
f t 和上下文分支 f s 生成的伪标签被用作对方的监督信号, 以避免分支生成自己的监督信号, 从而无法检测自身的