
Page 204 - 《软件学报》2025年第12期
P. 204
吴信东 等: 华谱通: 基于知识推理的家谱问答大语言模型 5585
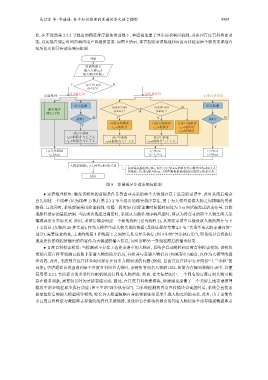
此, 在不改动第 2.3.2 节提出的路径排序算法的前提下, 华谱通部署了异步请求响应机制, 并协同百度百科检索功
能, 以实现在规定时间内响应用户问题的需求. 如图 9 所示, 本节按照家谱推理和百度百科检索两个模块来详细介
绍所提出的异步请求响应机制.
开始
家谱图谱 G
输入人物 a, b
最大响应时限 t
Y (a G) and N
(b G)?
家谱推理 异步执行① 异步执行② 百度百科检索
时长监测 (a ∉G) and (a G) and N 时长监测
路径排序 (b G) ? (b∉G) ?
(第2.3.2 节) N
N Y Y N
超时? 超时?
百度百科检索 百度百科检索 百度百科检索
Y
r a =a的简介 r b =b的简介 r a =a的简介 Y
r b =b的简介
从G中获取
r a =a的简介与上下文 从G中获取 从G中获取
r b =b的简介与上下文 r b =b的简介与上下文 r a =a的简介与上下文
r 1 =关系路径 r 1 =None r 1 =None
r 2 =None r 2 = r a ∪r b r 2 =None
大模型根据r 1 ∪r 2 回答a和b的关系
获取最先输出的r 1 和r 2 , 取其中不为None的值作为大模型回答a和b关系
的依据; 若r 1 和r 2 都为None, 大模型则根据预训练知识回答a和b的关系。
结束
图 9 华谱通异步请求响应机制
● 家谱推理模块: 触发该模块的前提条件是待查寻关系的两个人物都存在于选定的家谱中. 此时系统后端会
首先创建一个线程 (记为线程 1) 执行第 2.3.2 节中提出的路径排序算法, 用于为大模型提供人物之间精确的关系
路径. 与此同时, 系统前端采用轮询机制, 每隔一段时间 (实际部署时间隔时间设为 3 s) 向后端发送请求信号, 以获
取路径排序的最优结果. 当请求次数超过阈值时, 系统认为路径排序响应超时, 即认为待查寻的两个人物之间关系
薄弱或没有实际关系. 此时, 系统后端会创建一个新的线程 (记为线程 2), 从指定家谱中直接获取人物的简介与上
下文信息 (人物的 26 种亲属), 作为大模型生成人物关系的依据 (具体过程参考第 2.5 节 “关系生成式跨家谱问答”
部分). 需要注意的是, 上述的线程 1 和线程 2 之间的关系为异步执行 (图 9 中的“异步执行①”), 即系统只会将执行
速度更快的线程所输出的内容作为大模型的输入信息, 同时忽略另一条线程滞后的输出结果.
● 百度百科检索模块: 当检测到不存在于选定家谱中的人物时, 系统会自动跳转到百度百科检索模块. 该模块
借助百度百科查询端口获取非家谱人物的简介信息, 并将其与家谱人物信息 (如果存在) 融合, 以作为大模型的提
示内容. 此外, 考虑到百度百科查询同样存在同名人物识别的问题 (例如, 目前百度百科中存在两份“十二金钗”的
词条), 华谱通在首次查询到某个百度百科同名人物时, 会将所有同名人物的 URL 和简介存储到数据库表中, 以便
复用第 2.3.1 节所提出的多条件匹配机制进行同名人物消歧. 然而, 在实际情况中, 一个同名的百度百科人物可能
存在极多词条, 需要较长时间才能存储完成. 因此, 在百度百科检索模块, 华谱通也部署了一个类似上述家谱推理
模块中的多线程异步执行功能 (图 9 中的“异步执行②”). 当系统检测到百度百科模块查询超时后, 系统会直接返
回空值给后续的大模型问答模块, 即允许大模型根据自身的预训练知识来生成人物之间的关系. 此外, 由于前期负
责百度百科检索与数据库表存储的线程并未被销毁, 系统后台会继续将剩余的同名人物信息全部存储到数据库表