
Page 490 - 《软件学报》2025年第10期
P. 490
韩凯 等: 用于二值神经网络的加宽和收缩机制 4887
300
λ 0.00010
250 λ 0.00030
λ 0.00050
#Retained channels 150 λ 0.00065
200
λ 0.00070
λ 0.00080
100
λ 0.00100
50
0
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
Layer
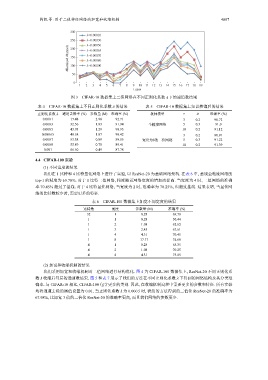
图 3 CIFAR-10 数据集上二值网络在不同正则化系数 λ 下的通道数结果
表 4 CIFAR-10 数据集上不同正则化系数 λ 的结果 表 5 CIFAR-10 数据集上知识蒸馏后的结果
正则化系数 λ 通道去除率 (%) 参数量 (M) 准确率 (%) 教师模型 τ µ 准确率 (%)
0.000 1 17.48 2.98 92.71 3 0.2 90.72
0.000 3 32.56 1.93 91.94 全精度网络 5 0.3 91.0
0.000 5 43.93 1.29 90.93 10 0.2 91.12
0.000 65 48.58 1.07 90.42 3 0.2 90.91
0.000 7 53.38 0.89 89.85 宽度为8的二值网络 5 0.3 91.22
0.000 8 55.89 0.78 89.41 10 0.2 91.39
0.001 66.50 0.49 87.78
4.4 CIFAR-100 实验
(1) 不同宽度的结果
我们在 1 比特和 4 比特量化网络上进行了实验, 以 ResNet-20 为基础网络架构. 在表 6 中, 基线全精度网络的
top-1 的精度为 69.78%. 对于 1 比特二值网络, 精度随着网络宽度的增加而提高. 当宽度为 4 时, 二值网络的准确
率 70.45% 超过了基线. 对于 4 比特量化网络, 当宽度为 2 时, 准确率为 70.25%, 也超过基线. 结果表明, 当量化网
络的比特数较少时, 需要更多的特征.
表 6 CIFAR-100 数据集上加宽不同宽度的结果
比特数 宽度 参数量 (M) 准确率 (%)
32 1 0.28 69.78
1 1 0.28 50.44
1 2 1.08 62.62
1 3 2.43 67.61
1 4 4.31 70.45
1 8 17.17 74.68
4 1 0.28 63.35
4 2 1.08 70.25
4 4 4.31 73.85
(2) 加宽和收缩机制的结果
我们采用加宽和收缩机制对二值网络进行结构优化. 图 4 为 CIFAR-100 数据集上, ResNet-20 不同正则化系
λ 收缩后每层的通道数结果. 图 5 和表 7 λ 下得到的网络结构及其分类准
数 展示了我们的方法在不同正则化系数
确率. 与 CIFAR-10 相比, CIFAR-100 包含更多的类别. 因此, 在收缩机制过程中需要更多的参数和特征. 所有实验
均将通道去除的阈值设置为 0.01. 当正则化系数 λ 为 0.000 5 时, 我们的方法得到的二值化 ResNet-20 的准确率为
67.98%, 比加宽 3 倍的二值化 ResNet-20 的准确率更高, 而且我们网络的参数更少.