
Page 170 - 《软件学报》2025年第10期
P. 170
李志强 等: SZZ 误标变更对移动 APP 即时缺陷预测性能和解释的影响 4567
代码分布维度将变更涉及的代码分布进行量化, 已有的研究表明代码分布与缺陷发生概率高度相关 [66] .
规模维度指代码变更的大小, 若代码有较大变更, 意味着代码的修改规模较大, 涉及的范围也更广, 因此更容
易引入缺陷 [67] .
目的维度仅有一个 Fix 度量, 该度量元用来表示变更是否修复了缺陷. 此前的研究发现, 修复了缺陷的变更出
现缺陷的概率更高, 并且很可能引入了新的缺陷 [68,69] .
历史维度用于描述开发人员修改代码所涉及的文件变更历史, 先前的研究中, 这些度量被证明在缺陷标注方
面表现良好. Matsumoto 等人 [70] 的研究指出, 许多开发人员修改过的文件中存在较多缺陷.
开发者经验维度对变更历史中的开发人员信息进行了量化, 根据开发人员此前提交的变更历史构建的度量.
Mockus 等人 [29] 的研究表明, 经验丰富的开发人员提交的变更一般不会引入缺陷.
在度量元的提取阶段, 首先, 使用 PyDriller [71] 读取项目的 Git 仓库, 使用 traverse_commits 函数遍历 Git 日志,
这些日志基于时间序列分布, 提取出相关信息后构建树形结构, 每个变更表示一个节点, 其孩子节点分别表示提交
中的信息, 例如每个变更的 Hash ID, 提交日期等, 并以 xml 格式保存, 便于后续复用. 其次, 遍历 xml 文件, 计算并
生成度量元. 最后, 整合所有度量元信息, 结合进一步的数据标注结果, 生成数据集. 下节本文将介绍数据标注的具
体步骤.
2.3 数据标注
本文使用 4 种不同的 SZZ 算法对数据进行标注, 即 B-SZZ、AG-SZZ、MA-SZZ 以及 RA-SZZ. 借助
PyDriller [71] 工具对每个移动 APP 的 Git 代码变更日志进行检索, Git 库中包含了所有开发人员提交的代码变更历
史, 使用正则表达式“(bug)|(fix)|(crash)|(fault)|(defect)|(problem)|(error)|(patch)|(wrong)”从中筛选出含有缺陷关键词
(例如 bug、fix、crash、fault 等) 的变更记录, SZZ 算法对这些已修复的缺陷变更进行溯源, 进而识别出含有缺陷
的代码行, 并标注哪些变更引入了缺陷.
对于本文选取的 17 个移动 APP 项目, 使用 4 种 SZZ 算法对每个 APP 项目进行数据标注, 每个 APP 的数据
集将包括 4 种 SZZ 算法的标注结果. Neto 等人 [15] 发现, RefDiff 工具在检查代码重构修改上的性能表现较好, RA-
SZZ 比 MA-SZZ 在识别缺陷方面更加准确. Fan 等人 [5] 对 RefDiff 工具进行了验证, 其中两位作者具有多年的
Java 开发经验, 在他们的验证下发现 RefDiff 在 10 个项目中达到了 97%–99% 的精度, 相比 MA-SZZ, RA-SZZ 产
生的噪音更小, 因此, 他们将 RA-SZZ 算法的标注结果作为真实标签实证比较不同 SZZ 算法的标注性能. 与该研
究工作一样, 本文将 RA-SZZ 算法的标注结果作为真实标签数据集, 因为 RA-SZZ 所标注的数据准确率最高. 其
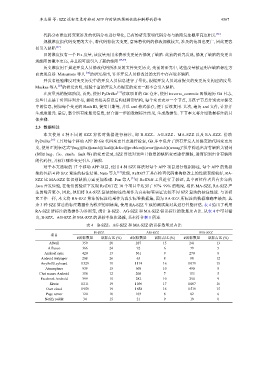
余 3 种 SZZ 算法的标注数据作为模型的训练集, 使用 RA-SZZ 生成的测试集对其进行性能评估. 表 4 给出了利用
RA-SZZ 所标注的数据作为参照集, 统计 B-SZZ、AG-SZZ 和 MA-SZZ 错误标注的数量及占比. 从表 4 中可以看
出, B-SZZ、AG-SZZ 和 MA-SZZ 的误标率依次递减, 基本符合表 1 所述.
表 4 B-SZZ、AG-SZZ 和 MA-SZZ 的误标数量及占比
B-SZZ AG-SZZ MA-SZZ
项目
#误标数量 误标占比 (%) #误标数量 误标占比 (%) #误标数量 误标占比 (%)
Afwall 359 20 267 15 241 13
Alfresco 366 24 92 6 79 5
Android sync 420 13 301 9 270 8
Android walpaper 208 26 63 8 98 12
AnySoftKeyboard 1 329 19 1 174 16 1 079 15
Atmosphere 939 15 608 10 490 8
Chat secure Android 356 12 208 7 153 5
Facebook Android 399 15 282 10 254 9
Kiwix 1 211 19 1 096 17 1 007 16
Own cloud 1 959 19 1 658 16 1 519 15
Page turner 124 10 103 8 82 6
Notify reddit 34 15 21 9 19 8