
Page 350 - 《软件学报》2025年第9期
P. 350
赵亚茹 等: 云边联邦学习系统下抗投毒攻击的防御方法 4261
防御算法: 本文中, 我们比较了所提出的 FedDiscrete 防御算法与现有经典的防御方法, 主要包括标准的
FedAvg, MKrum, Median 和 FoolsGold. 具体介绍如下.
FedAvg : 一种常用的 FL 算法, 通过加权平均来聚合模型参数. 其基本思想是将本地模型参数上传到服务器,
[3]
计算所有模型参数的平均值, 然后分发平均值给所有本地客户端, 迭代训练直至满足收敛条件.
MKrum [48] : 在 Krum 算法的基础上, 基于欧氏距离的拜占庭容错 ML 算法, 通过计算并求和每两个梯度之间的
欧氏距离, 搜索出具有最小分数的梯度, 通过对选择的若干个梯度求平均来更新模型参数, 直至模型收敛.
Median [49] : 使用聚合器对所有客户端的参数更新值排序, 并在每次迭代中选择中值作为全局模型的贡献.
FoolsGold [33] : 通过对恶意更新的学习率进行惩罚来解决攻击者问题, 然后, 衡量每个更新和全局模型之间的
角度差异实现恶意更新的检测, 且其能够防御 sybil 攻击.
此外, 我们还对比了应用在不同攻击场景下的较新颖的防御方法, 包括 Krum [48] , FLTrust [10] , Trimmed-mean [50] ,
Auror [51] , PEFL [30] , RobustFL [15] , CONTRA [52] , 以及面向离散更新空间的防御方法 [23−25] , 详细的描述在第 1 节.
评估指标: 为了准确地评估实验结果, 我们引入了多个评价指标, 包括模型准确度 (Acc), 类精度 (Cpre), 类召
回率 (Crec) 和 F1-score (F1). 具体地, Acc 用于衡量在所有预测样本中预测正确的样本所占的比例; Cpre 用于评
估正确预测的正例样本占所有预测的正例样本的比例; Crec 指正确预测的正例样本占所有正例样本的比例, F1
Cpre 的调和平均值, 表达为公式 (2)–公式 , F1, 说明防御效
定义为 Crec 和 (4) 所示. 我们知道越高的 Crec Cpre 和
果越好. 进一步地, 我们也采用混淆矩阵和攻击成功率 ( ASR) 评估防御方法的有效性和鲁棒性. 具体而言, 混淆矩
阵依赖于真实标签和预测标签, 用于直观地观察实施 FedDiscrete 防御后的分类效果; ASR 用于衡量带有源标签的
目标样本被错误分类为攻击者渴望的目标标签的比例. 最后, 我们对计算代价和通信开销进行评估以讨论
FedDiscrete 的可行性和高效性. 特别地, 在本文中, 我们主要集中于客户端-边缘服务器端的上行通信成本.
Cpre = TP/(TP+ FP) (2)
Crec = TP/(TP+ FN) (3)
Crec×Cpre
F1 = (4)
2×(Crec+Cpre)
其中, TP (true positive) 表示分类器将正例正确分类的样本数, FN (false negative) 表示分类器将正例错误分类为
反例的样本数, FP (false positive) 表示错误地分类为正例的反例样本的数量.
值得注意的是, 对于每个测试, 我们均执行了 5 次实验并计算评价指标的平均值, 以避免结果的随机性.
4.2 实验结果与分析
在本节中, 我们从多个角度展示了我们的实验结果并进行详细的分析和讨论.
4.2.1 无攻击者投毒场景的性能评估
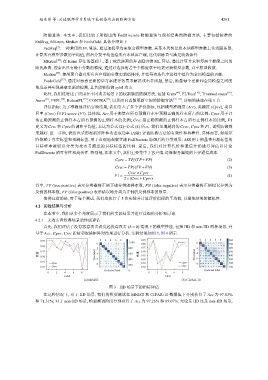
首先, 我们评估了没有恶意攻击者发起投毒攻击 ( b = 0) 情况下的模型性能, 包括 IID 和 non-IID 两种场景, 并
,
,
基于 Acc Cpre Crec 指标和混淆矩阵对结果进行分析, 实验结果如图 3, 图 4 所示.
0 2 4 6 8 0.85 0 2 4 6 8 800
0.99
0 954 1 000 0.80 0 779 779 700
954
0.98 1 118 843 843
1 118
2 1 008 1 001 800 0.75 2 676 410 600
676
1 008
410
1 001
数值 0.97 True label 4 966 966 874 874 600 数值 0.70 True label 4 659 659 578578 500
0.65
400
0.96
944
849
750
0.95 6 944 994 994 400 0.60 6 849 750 300
Cpre 8 963 0.55 Cpre 8 822 822 200
963
765
0.94 Crec 961 961 200 0.50 Crec 765 100
Predicted label 0 Predicted label
0 2 4 6 8 0 2 4 6 8
Label Label
(a) MNIST (b) CIFAR-10
图 3 IID 场景下的指标评估
在这种情况下, 对于 IID 场景, 我们的模型测试在 MNIST 和 CIFAR-10 数据集下分别获得了 Acc 为 97.83%
和 71.31%; 对于 non-IID 场景, 模型测试阶段分别获得了 Acc 为 97.26% 和 69.07%. 无论是 IID 还是 non-IID 场景,