
Page 468 - 《软件学报》2025年第7期
P. 468
吴桦 等: 面向 HTTP/2 流量多路复用特征的加密视频识别方法 3389
TLS 协议对数据的封装过程中, 有时会将 DATA 帧数据切分为连续的、等长的 TLS 记录. 为了更好地刻画 CDU
的特征, 并计算 CDU 中包含的 DATA 帧的个数, 属于同一 DATA 帧的多个 TLS 记录应当被合并. 因此, 本文将一
条流中出现次数超过阈值的连续、等长的 TLS 记录定义为这条流的频繁项, 然后将训练集中所有 CDU 对应的
TLS 记录序列进行合并频繁项操作. 通过这种合并频繁项的操作, 使得特征向量中包含的特征值更贴近真实
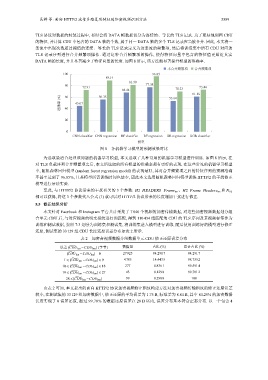
DATA 帧的长度, 并且显著减少了特征向量的长度. 如图 8 所示, 该方法能显著提升模型的准确率.
未合并频繁项 合并频繁项
100 96.85
89.14
81.50
80 77.38
72.91 73.44
68.44 70.23
61.16
准确率 (%) 40 45.07
56.35
60
53.64
20
0
CNN classifier CNN regression RF classifier RF regression GB regression XGB classifier
模型
图 8 各机器学习模型的预测效果对比
为选取最适合处理该问题的机器学习模型, 本文选取了几种常用的机器学习模型进行训练. 如图 8 所示, 在
对 TLS 负载序列合并频繁项之后, 本文所选取的所有模型的准确率都有更好的表现. 在这些常见的机器学习模型
中, 随机森林回归模型 (random forest regression model) 的表现最好, 其对合并频繁项之后的特征序列的预测准确
率甚至达到了 96.85%, 且其模型所需训练时间也最少, 因此本文选用随机森林回归模型训练 HTTP/2 的干扰修正
模型进行后续实验.
至此, 与 HTTP/2 协议带来的干扰有关的 3 个参数: H2_HEADERS _Frame len 、 H2_Frame_Headers len 和 N H2
都可以获得, 将这 3 个参数代入公式 (1) 就可以对 HTTP/2 协议带来的长度增加干扰进行修正.
5.5 修正结果分析
本文针对 Facebook 和 Instagram 平台共计采集了 7 846 个视频的加密传输数据, 对这些加密视频数据划分组
合单元 CDU 后, 与对应视频的明文指纹进行预匹配, 得到 110 434 组匹配的 CDU 的 TLS 序列及其视频标签作为
训练和测试数据, 按照 7:3 划分为训练集和测试集, 将训练集送入模型进行训练, 随后使用训练好的模型进行修正
还原, 测试集的 33 129 组 CDU 长度还原误差分布如表 2 所示.
表 2 加密音视频数据分组数据单元 CDU 修正还原误差分布
]
误差 (CDU len −CDU len ) (字节) 数据量 占比 (%) 累计占比 (%)
| ] 27 925 84.291 7 84.291 7
CDU len −CDU len | = 0
1 ⩽ | ] 4 785 14.443 5 98.735 2
CDU len −CDU len | ⩽ 9
10 ⩽ | ] 277 0.836 1 99.591 4
CDU len −CDU len | ⩽ 18
19 ⩽ | ] 43 0.129 8 99.701 2
CDU len −CDU len | ⩽ 27
28 ⩽ | ] 99 0.298 8 100
CDU len −CDU len |
由表 2 可知, 本文提出的面向 HTTP/2 协议加密视频修正指纹构建方法对加密视频传输指纹的修正还原误差
较小, 在测试集的 33 129 组加密数据中, 修正还原的平均误差为 1.75 B, 标准差为 8.84 B, 其中 84.29% 的加密数据
长度实现了 0 误差还原, 超过 99.70% 的数据还原误差在 28 B 以内, 误差分布基本符合正态分布. 以一个包含 4