
Page 432 - 《软件学报》2025年第7期
P. 432
王瀚橙 等: 无锁并发布谷鸟过滤器 3353
次串行执行, 无法随线程数量增加获得性能提升. 加之随线程数量增加, 不同线程对锁的竞争增加, 导致执行时间
随线程数量增多反而不断增加. 此外, 在单线程场景下, 无锁并发布谷鸟过滤器为支持并发操作而引入的设计会产
生无谓的开销, 从而导致单线程性能较低. 针对上述问题, 一种可行的解决方案为: 若过滤器使用场景仅需要单线
程运行, 则可将无锁并发布谷鸟过滤器直接退化成传统单线程布谷鸟过滤器, 从而避免为支持并发而引入额外的
开销.
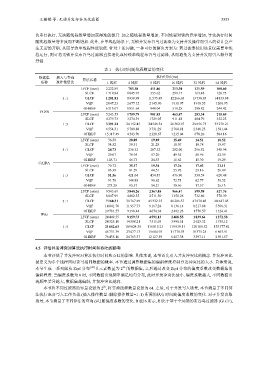
表 1 执行时间随线程数量的变化
数据集 插入与查询 算法名称 执行时间 (ms)
名称 操作数量比 1 线程 4 线程 8 线程 16 线程 32 线程 64 线程
LFCF (ours) 2 222.85 783.38 411.86 213.30 121.59 100.60
SLCF 1 719.84 1 045.97 555.62 299.17 163.48 128.75
3:1 GLCF 1 281.81 8 930.98 11 575.49 12 266.68 13 730.83 14 853.98
VQF 2 047.23 2 677.12 2 145.90 1 938.97 1 918.55 1 200.95
OHBBF 6 315.07 1 851.64 940.04 518.28 290.82 244.42
YCSB
LFCF (ours) 5 243.55 1 759.79 901.83 463.87 253.34 215.69
SLCF 4 379.73 3 274.39 1 729.05 911.48 484.79 352.25
1:3 GLCF 3 391.24 24 152.45 24 548.34 26 302.97 29 656.75 33 278.21
VQF 6 554.31 5 789.88 3 731.29 2 760.81 2 340.23 1 581.44
OHBBF 15 317.49 4 543.70 2 328.67 1 235.04 678.20 504.16
LFCF (ours) 36.50 28.89 19.89 15.49 14.51 18.52
SLCF 34.52 39.51 21.28 18.07 18.78 19.97
3:1 GLCF 24.73 236.32 267.32 282.00 296.52 348.96
VQF 29.07 70.95 57.20 49.34 48.96 42.39
OHBBF 105.71 46.73 24.53 15.62 15.30 19.29
CAIDA
LFCF (ours) 70.72 35.17 19.34 17.26 17.02 21.11
SLCF 83.38 81.29 44.51 25.92 23.16 26.89
1:3 GLCF 51.56 421.04 454.87 476.90 530.59 620.48
VQF 91.78 148.88 96.62 72.75 62.77 50.52
OHBBF 273.29 95.57 54.21 30.56 17.57 26.13
LFCF (ours) 9 543.69 3 840.26 2 367.05 966.47 599.98 527.76
SLCF 8 847.99 4 862.55 2 511.50 1 351.26 732.60 578.39
3:1 GLCF 7 160.31 38 767.69 45 332.15 46 286.37 47 670.45 60 647.45
VQF 14 841.70 11 957.73 9 167.24 8 136.14 8 217.88 5 506.31
OHBBF 29 781.57 9 398.44 4 674.94 2 492.28 1 770.57 1 124.41
Wiki
LFCF (ours) 24 449.55 9 159.73 4 591.13 2 408.55 1 839.64 1 272.58
SLCF 24 325.10 14 308.21 7 515.03 3 990.51 2 625.32 1 758.12
1:3 GLCF 21 652.63 109 624.30 116 815.23 119 939.11 120 100.52 155 377.62
VQF 45 731.39 23 477.13 15 684.93 11 778.93 10 375.25 6 863.91
OHBBF 76 435.16 24 763.37 12 127.59 6 457.38 3 597.11 2 591.57
4.5 评估并发冲突对算法执行时间和吞吐的影响
本节评估了并发冲突对算法执行时间和吞吐的影响. 具体来说, 本节首先引入并发冲突比的概念. 并发冲突比
被定义为多个线程同时读写相同数据的概率. 本节通过调整数据集的偏斜程度控制并发冲突比的大小. 具体来说,
本节生成一系列服从 Zipf 分布 [49] 且元素数量为 2 的数据集, 之后通过改变 Zipf 分布的偏度系数改变数据集的
26
偏斜程度. 当偏度系数为 0 时, 不同数据出现频率满足均匀分布, 此时并发冲突比最小. 偏度系数越大, 不同数据出
现频率差异越大, 数据集越偏斜, 并发冲突比越高.
本节将不同过滤器的容量设置为 2 , 将实验线程数量设置为 64. 之后, 对于并发写入场景, 本节测量了不同算
26
法执行混合写入工作负载 (插入操作数量:删除操作数量=1:1) 所需的执行时间随偏度系数的变化. 对于并发读取
场景, 本节测量了不同算法的查询吞吐随偏度系数的变化. 如图 6 所示, 相比于基于全局锁的布谷鸟过滤器 (GLCF),