
Page 284 - 《软件学报》2025年第7期
P. 284
秦政 等: 面向 Apache Flink 流式分析应用的高吞吐优化技术 3205
位线会被自动释放, 不会造成额外的空间占用. 在大部分场景中, 我们认为这一开销是可以接受的. 对于计算开销,
当事件处理时, 需要更新相应键的水位线, 涉及查找水位线、比较时间戳、写入操作等, 其开销取决于键分布情
况, 数据动态变化情况以及具体计算任务. 因此, 在 Trilink 系统中, 同样支持 N-键级水位线机制, 即 N 个 Key 共享
同一水位线, 从而达到空间开销与系统性能间的均衡. 键级水位线机制实际提供了一种细粒度的控制方式, 用户可
以在键级和子任务级间自主调控, 从而达到高性能高可用.
5
4
吞吐率提升 3 2
1
0
KeyBy Local Merge Global Ahead KeyBy
Merge
KeyBy Local Merge Global Merge Ahead KeyBy
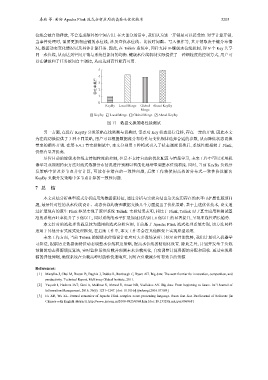
图 17 数据交换策略性能测试
另一方面, 在进行 KeyBy 分发策略在线监测与切换时, 需要对 Key 状态进行迁移, 存在一定的开销. 因此本文
为在线切换提供了 3 种不同策略, 用户可以根据数据流分布特性与变化规律选择合适的参数, 从而降低状态切换
带来的额外开销. 在第 6.4.1 节实验测试中, 本文分别用 3 种模式引入了状态调度切换后, 系统性能相较于 Flink,
仍然有显著提高.
尽管目前的键级水位线支持细粒度的控制, 但是不支持自动的优化配置与增量学习, 未来工作中可以采用机
器学习或规则约束方法对流式数据分布情况进行预测以智能化地增量调整水位线粒度. 同时, 当前 KeyBy 负载分
发策略中涉及多节点并行计算, 可能存在潜在的一致性问题, 后续工作将使用高效的分布式一致性协议解决
KeyBy 负载分发策略中多节点计算的一致性问题.
7 总 结
本文总结分析典型流式分析应用的数据流特征, 通过分析与实验总结出这类应用存在的水平可扩展性瓶颈问
题, 最后针对性的从水位线设计、动态负载均衡和数据交换几个方面提出了优化策略. 基于上述优化技术, 论文通
过扩展现有的原生 Flink 框架实现了原型系统 Trilink. 实验结果表明, 相比于 Flink, Trilink 对于真实应用和测试基
准的系统吞吐率提升了 5 倍以上, 同时系统的水平扩展加速比得到 1.6 倍以上的显著提升, 呈现亚线性增长趋势.
本文针对的流处理负载是较为通用的流式分析应用, 目前基于 Apache Flink 流式处理系统实现, 该方法同样
适用于其他分布式流式处理框架, 在后续工作中, 本文工作者会在其他框架上实现原型系统.
未来工作方面, 当前 Trilink 的键级水位线设计在应对大多数场景时已显示出性能优势, 我们计划引入机器学
习算法, 根据历史数据流特征动态调整水位线粒度策略, 提高水位线的精细化设置. 除此之外, 计划开发基于负载
预测的动态资源调度算法, 实时监控系统负载并预测未来负载变化, 自动调整计算资源的分配和回收. 通过实现资
源的弹性伸缩, 确保系统在负载高峰时能够快速响应, 同时在负载减少时有效节约资源.
References:
[1] Manyika J, Chui M, Brown B, Bughin J, Dobbs R, Roxburgh C, Byers AH. Big data: The next frontier for innovation, competition, and
productivity. Technical Report, McKinsey Global Institute, 2011.
[2] Yaqoob I, Hashem IAT, Gani A, Mokhtar S, Ahmed E, Anuar NB, Vasilakos AV. Big data: From beginning to future. Int’l Journal of
Information Management, 2016, 36(6): 1231–1247. [doi: 10.1016/j.ijinfomgt.2016.07.009]
[3] Fu XD, Wu ZL. Formal semantics of Apache Flink complex event processing language. Ruan Jian Xue Bao/Journal of Software (in
Chinese with English abstract). http://www.jos.org.cn/1000-9825/6968.htm [doi: 10.13328/j.cnki.jos.006968]