
Page 270 - 《软件学报》2025年第7期
P. 270
秦政 等: 面向 Apache Flink 流式分析应用的高吞吐优化技术 3191
工作总结分析了影响系统性能的潜在瓶颈. 首先, 系统通过计算和传递水位线来提高局部计算的相对正确性, 水位
线机制贯彻处理生命周期. 然而, 水位线机制会带来额外的等待时间或时序耦合, 影响系统性能. 此外, 流式处理应
用的核心功能主要围绕 KeyBy 算子展开, 其涉及数据分发与节点间的数据传输, 数据分发的均衡度以及节点间传
输的效率, 对系统的整体性能产生重大影响.
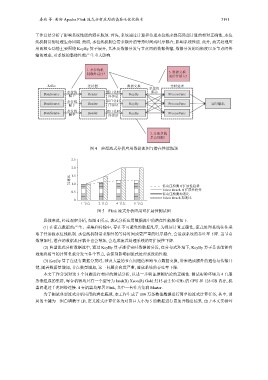
1. 水位线机
制额外乱序? 3. 数据交换
通信开销大?
Kafka 连接器 数据交换 实时处理
水位线
水位线 窗口化时 流动
DataSource Reader KeyBy ProcessFunc
赋予 序保证
水位线 窗口化时
DataSource Reader KeyBy ProcessFunc 实时输出
赋予 序保证
水位线 窗口化时
DataSource Reader KeyBy ProcessFunc
赋予 序保证
2. 分配负载
是否均衡?
图 4 典型流式分析应用数据流图与潜在性能瓶颈
2.5
2.0
加速比 1.5
1.0
低电压检测可扩展性趋势
Yahoo Bench 可扩展性趋势
0.5
低电压检测加速比
Yahoo Bench 加速比
0
1 节点 2 节点 4 节点 8 节点
图 5 Flink 流式分析应用可扩展性测试图
具体来说, 经过观察分析, 如图 4 所示, 流式分析应用数据流中的潜在性能瓶颈如下.
(1) 在流式数据的产生、采集和传输中, 存在不可避免的数据乱序, 为保证计算正确性, 流式处理系统往往采
取子任务级水位线机制. 水位线机制带来额外的等待时间或更严重的时序耦合, 会造成系统的吞吐率下降. 当节点
数增加时, 潜在的数据乱序耦合也会增加, 会造成流式处理系统的可扩展性下降.
(2) 典型流式分析数据流中, 通过 KeyBy 算子进行实时数据的分发, 在分布式环境下, KeyBy 算子是否能够有
效地将相当的计算负载分发至各个节点, 会深刻影响到流式处理系统的性能.
(3) KeyBy 算子在进行数据分发时, 涉及大量的节点间通信和跨节点数据交换, 带来造成额外的通信与传输开
销, 随着数据量增加, 节点数量增加, 这一问题会愈发严重, 造成系统的吞吐率下降.
本文工作分别对这 3 个问题进行相应的测试分析, 以进一步验证推测结论的正确性. 测试实验环境为 4 台服
务器组成的集群, 每台机器均具有一个型号为 Intel(R) Xeon(R) Gold 5215 @ 2.50 GHz 的 CPU 和 128 GB 内存, 机
器间通过千兆网络连接. 4 台机器均部署 Flink, 其中一台作为集群 Master.
为了测试典型流式分析应用的潜在瓶颈, 本工作生成了 100 万条数值数据进行简单的流式计算任务, 其中, 消
息的主键为一组自增数字 ID, 定义流式计算任务为对窗口大小为 5 的数据进行累加并输出结果. 由于本文实验环