
Page 92 - 《软件学报》2025年第5期
P. 92
1992 软件学报 2025 年第 36 卷第 5 期
Java Java Java
15 000 15 000 15 000
128 MB 12 500 256 MB 12 500 512 MB
12 500
冷启动性能 (ms) 10 000 10 000 10 000
7 500
7 500
7 500
5 000
2 500 5 000 5 000
2 500
2 500
0 0 0
亚马逊 谷歌 微软 阿里巴巴 亚马逊 谷歌 微软 阿里巴巴 亚马逊 谷歌 微软 阿里巴巴
Java Java
15 000 15 000
1 024 MB 12 500 2 048 MB
12 500
冷启动性能 (ms) 10 000 10 000
7 500
7 500
5 000
2 500
2 500 5 000
0 0
亚马逊 谷歌 微软 阿里巴巴 亚马逊 谷歌 微软 阿里巴巴
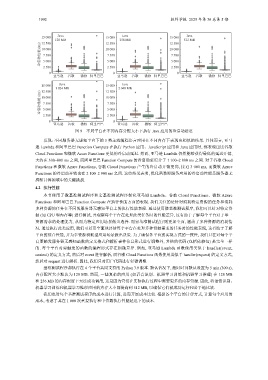
图 9 不同平台在不同内存分配大小下执行 Java 应用的冷启动延迟
发现: 不同服务器无感知平台下的 3 类主流编程语言应用在不同内存下表现出相似的结果. 具体而言, 亚马
逊 Lambda 和阿里巴巴 Function Compute 在执行 Python 应用、JavaScript 应用和 Java 应用时, 都表现出比谷歌
Cloud Functions 和微软 Azure Functions 更低的冷启动延迟. 然而, 亚马逊 Lambda 仍然能够获得最低的延迟开销,
大约在 300–800 ms 之间, 而阿里巴巴 Function Compute 的冷启动延迟介于 1 100–2 800 ms 之间. 对于谷歌 Cloud
Functions 和微软 Azure Functions, 谷歌 Cloud Functions 产生的冷启动开销更高, 接近 3 000 ms, 而微软 Azure
Functions 的冷启动开销也在 2 100–2 900 ms 之间. 这些结果表明, 优化函数即服务应用的冷启动性能是服务器无
感知计算领域中的关键挑战.
4.2 执行性能
本节使用了微基准测试程序和宏基准测试程序探究亚马逊 Lambda、谷歌 Cloud Functions、微软 Azure
Functions 和阿里巴巴 Function Compute 在执行性能方面的表现. 我们关注的是针对消耗特定资源的任务和消耗
多种资源的任务在不同的服务器无感知平台上的执行性能表现. 通过使用微基准测试程序, 我们可以针对特定资
源 (如 CPU 和内存等) 进行测试, 并观察每个平台在处理此类任务时的性能差异, 这有助于了解每个平台对于单一
资源需求的处理能力, 从而为特定应用场景做出选择. 而宏基准测试程序则更加全面, 涵盖了多种资源的消耗情
况. 通过执行此类应用, 我们可以更全面地评估每个平台在处理多种资源需求的任务时的性能表现, 这有助于了解
平台的综合性能, 并为多资源消耗型应用场景做出决策. 为了确保各平台的实现方式的一致性, 我们只在对每个平
台要触发服务器无感知函数的定义格式和解析事件信息形式进行调整外, 其他的代码 (包括依赖包) 是完全一样
的. 每个平台对要触发的函数的编程形式存在细微差异. 例如, 亚马逊 Lambda 函数使用类似于 handler(event,
context) 的定义方式, 然后对 event 进行解析, 而谷歌 Cloud Functions 函数使用类似于 handler(request) 的定义方式,
然后对 request 进行解析. 因此, 我们只对用户代码进行轻微调整.
基准测试程序都执行在 4 个平台共同支持的 Python 3.9 版本. 默认情况下, 超时时间默认设置为 5 min (300 s),
内存配置大小默认为 128 MB. 然而, 一些复杂的应用 (如语音识别、机器学习训练和机器学习推理) 在 128 MB
和 256 MB 的内存配置下无法成功调用, 这是因为它们在实际执行过程中需要更多的内存资源. 因此, 将语音识别、
机器学习训练和机器学习推理应用的内存大小都提高到 512 MB, 以确保它们被成功运行和公平地比较.
我们也对每个基准测试程序的成本进行计算, 进而开展成本比较. 根据各个平台的计费方式, 计算每个应用的
成本, 考虑了其在 1 000 次重复执行和中位数执行性能延迟下的成本.