
Page 28 - 《软件学报》2025年第5期
P. 28
1928 软件学报 2025 年第 36 卷第 5 期
从而提高半监督学习生成的伪标签质量; (2) 在选择无标签样本时, 引入权重机制, 结合初始训练模型精确度和伪
无标签样本概率分数, 为所选择样本赋予权重值, 重点缓解半监督模型中, 伪标签数量与质量间难以达成 trade-off
导致模型效果不稳定的问题. 本文基于多个企业项目, 展开了多组对比实验, 验证了本文所提框架在当前真实企业
项目软件可追踪性恢复任务上的有效性.
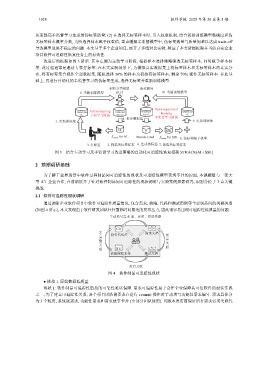
改进后的框架如图 3 所示. 其中左侧为主动学习阶段, 根据样本选择策略筛选无标签样本, 同时赋予样本标
签. 此过程通常是邀请专家打标签, 在本文实验场景下, 为模拟真实数据集上有标签样本和无标签样本的真实分
布, 将有标签集合视作全部数据集, 随机选择 30% 的样本为初始有标签样本, 剩余 70% 视作无标签样本. 在此基
础上, 再进行自动化的半监督学习的伪标签生成, 选择无标签并重新训练模型.
初始分类模型 迭代循环
5. 重新训练模型 f(I,C) 10. 重新训练模型
Semi-supervised
Labeled data Active learning Unlabeled Unlabeled learning Labeled data
D l 主动学习阶段 data D u data D u D l
1. 拆分数据集 半监督学习阶段
4. 更新训练集 9. 更新训练集
AL P SSL
S subset for AL Pseudo-label S subset for SSL 8. 伪标签赋予权重
3. 打标签 2. 筛选无标签样本 6. 生成伪标签 7. 筛选无标签样本
图 3 结合主动学习及半监督学习改进策略的自动化可追踪性恢复框架 STRACE(AL+SSL)
2 前期调研基础
为了解工业界场景中软件过程制品间可追踪性的现状及可追踪性模型表现不佳的原因, 本课题组与一家大
型 ICT 企业合作, 在前期展开了针对软件制品间可追踪性的现状调研与实验案例探索研究, 识别分析了 3 点关键
挑战.
2.1 软件可追踪性现状调研
通过调研企业软件项目中软件可追踪性质量情况, 包含需求, 缺陷, 代码和测试用例等主要制品间的关联关系
(如图 4 所示), 本文发现由于软件研发团队往往面临时间紧迫的发布压力, 因此很容易出现可追踪性低质量的问题.
手动填写需求 ID、延时、错误关联
Git
不 软件代码库 需求文档 没
完 有
整 关
关 联
联 ITS
缺陷跟踪系统 测试文档
没有关联
图 4 软件制品可追踪性现状
● 挑战 1. 原始数据低质量
现状 1: 软件制品可追踪性链接的可靠性难以保障. 需求可追踪性属于合作企业保障其可信软件的最佳实践
之一, 为了建立可追踪性关系, 各个项目团队被要求在进行 commit 操作时手动填写功能性需求编号. 需求具体分
为 3 个粒度, 系统级需求, 功能性需求和需求故事卡片 (少部分团队使用). 且版本发布前保证所有需求必须关联代