
Page 150 - 《软件学报》2025年第5期
P. 150
2050 软件学报 2025 年第 36 卷第 5 期
这些向量表示对训练集中的正负样本 (在每一轮训练时重新采样等比例的负样本) 进行有监督学习 [33] . 具体来讲,
利用节点向量求得样本中节点对的内积, 然后与标签求损失, 最后反向传播更新参数.
通过使用所需预测的节点对 v i 和 h (L) h (L) , 计算二者的内积以判断其存在连边的概率:
v j 的节点特征向量 i 和 j
( )
(L)
p i j = σ h ·h (L) (10)
i j
其中, σ 是激活函数, 使用的是 Softmax. 为了解决网络稀疏性问题, 使用负采样的方式平衡数据类别. 对于每个存
在连边的正边对 (G i , G j ), 对于负采样得到的负样本的节点对 (G i , G m ), 使用交叉熵损失函数优化模型:
∑
( )
L = −log p ij −E m∼p j log(1− p im ) (11)
( G i ,G j) ∈G
3 实验设计与结果分析
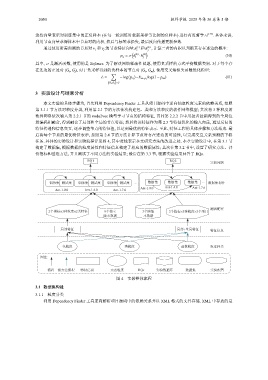
本文实验的具体步骤为, 首先利用 Dependency Finder 工具从项目源码中逆向抽取粒度元素的依赖关系, 按照
第 3.1.1 节方法对粒度分类, 利用第 2.1 节的方法依次构建包、类和方法粒度的软件网络模型; 其次将 3 种粒度的
软件网络依次输入第 2.2.1 节的 node2vec 模型学习节点的结构特征, 再同第 2.2.2 节中用拉普拉斯得到的全局位
置编码相融合, 得到融合了局部和全局的节点特征; 然后将该特征作为第 2.3 节特征优化的输入向量, 通过反复的
特征传递和信息交互, 逐步调整节点的特征值, 以达到最优的特征表示. 至此, 特征工程的具体步骤和方法结束. 最
后将每个节点的最优特征表示, 按照第 2.4 节的方法计算节点对存在连边的可能性, 以完成交互关系预测的下游
任务. 具体的实验设计和实验流程详见图 4, 其中蓝线表示本文研究方法的改进之处. 本章实验设计中, 在第 3.1 节
构建了数据集, 根据数据的粒度属性和特征信息构建了相应的数据属性; 其次在第 3.2 节中, 设置了研究方法、评
价指标和基准方法, 并且测试了不同方法的实验结果; 最后在第 3.3 节, 根据实验结果回答了 RQs.
RQ1 RQ2
实验问题
训练集 测试集 训练集 测试集 训练集 测试集 ... 数据集 数据集 数据集 ... 数据集划分
Ant-1.0.0 Ant-1.4.0 Ant-1.7.6
Ant-1.0.0 Ant-1.4.0 Ant-1.7.6
测试配置
2个指标×3种粒度×2类特征 9个独立 3个跨版 2个指标×3种粒度×3个项目
版本数据 本数据
局部特征 局部+全局特征 特征信息
包粒度 类粒度 函数粒度 粒度种类
图注:
流程 新方法流程 特征信息 元素粒度 RQs 实验数据库 数据集 实验配置
图 4 实验整体流程
3.1 数据集构建
3.1.1 粒度分类
利用 Dependency Finder 工具逆向解析项目源码中的依赖关系并以 XML 格式的文件存储. XML 中存放的是