
Page 95 - 《软件学报》2024年第6期
P. 95
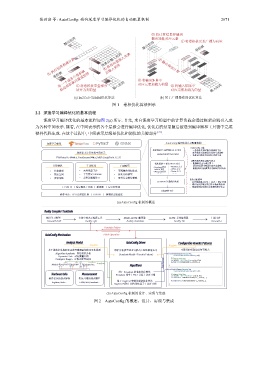
张洪滨 等: AutoConfig: 面向深度学习编译优化的自动配置机制 2671
⑤ 将计算结果存储到
输出矩阵 输出矩阵 输出矩阵对应元素 ① 将卷积核元素广播为向量
卷积核
② 将列向量插入变换
④ 执行矩阵相乘计算 变换后输入矩阵 ④ 融合乘加计算
后输入矩阵
③ 一个或多个卷积核 输入矩阵 ③ 将输出矩阵中 ② 将输入矩阵中 输入矩阵
卷积核
组成卷积核向量或矩阵
对应元素加载为向量
① 将卷积核重叠部分
展开为列向量
对应元素加载为向量
(a) lm2Col+GEMM优化算法 (b) 基于广播操作的优化算法
图 1 卷积优化算法图示
2.2 深度学习编译优化的基本流程
深度学习编译优化的基本流程如图 2(a) 所示. 首先, 来自深度学习模型中的计算负载会通过框架前端引入成
为各种中间表示. 接着, 在中间表示的各个层级会进行编译优化, 优化后的结果随后被送到编译器和工具链中完成
硬件代码生成. 在这个过程中, 中间表示层级是优化和调优的关键部分 [23] .
深度学习框架 AutoConfig 编译优化自动配置机制
AutoConfig 目标
承接深度学习模型的 MLIR 方言 - 一次优化实现适配多种硬件平台
深度学习计算负载中间表示 - 配置优化算法的最佳代码生成策略
Linalg Dialect/TOSA Dialect - 选择最佳优化算法进行代码生成
TVM Relay IR 中间表示, TorchDynamo 图表示, MLIR Linalg/TOSA 方言等
可配置的代码生成重写模式
优化算法 + 核心 MLIR 方言 - 粗颗粒度重写高层算子
自动调优 手动优化 自动配置 - 优化算法的可配置代码生成策略
- Broadcast 算法 - MemRef 方言 - 根据优化分析模型自动配置代码生成
• 代价模型 • 高性能算子库 • 可配置的代码生成 - Im2Col 算法 - Affine 方言
- Vector 方言
- Winograd 算法
• 搜索空间 • 平台特定 Intrinsic • 优化分析模型 ... ... ... ...
• 搜索策略 • 高性能编程接口 • 硬件信息收集策略
优化分析模型
LLVM IR+汇编代码生成 - 总开销建模为计算 + 访存 + 特定开销
- 硬件信息提取结果指导参数配置范围
- 根据算法特性构建动态测量程序集合
LLVM IR | 特定硬件工具链 | 模拟器 | 运行时环境 rw.create<vector::BroadcastOp>(..., vectorTy, ...);
目标硬件平台
硬件平台:CPU 高性能扩展 | GPGPU | 领域特定加速器
(a) AutoConfig 机制的概述
深度学习模型 多级中间表示编译工具 MLIR-LLVM 翻译器 LLVM 系统编译器 目标文件
forward.mlir buddy-opt buddy-translate buddy-llc forward.o
Populate Pattern
Fetch Operation
Register Register
基于静态信息提取和动态开销测量的优化分析模型 维护分析模型和重写模式之间的映射关系 可配置的代码生成重写模式
Algorithm Analysis:算法特性分析 void BroadcastPattern (Operation *op,
Dynamic Cost:动态测量开销 {Analysis Model->Rewrite Pattern} ... ... ConversionPatternRewriter &rw,int64_t vs) {
Configure Range:参数可配置范围 // Configure Vector Type.
M Implement auto vectorTy = mlir :: VectorType::get ({vs}, f32);
Analyze ... ...
Model=ƛ(vs)FPO+ƛ(vs)DM+ ƛ(vs)specIns i }
i+1
void Img2ColPattern (Operation *op,
基于 Broadcast 的卷积优化算法 ... ... ConversionPatternRewriter &rw, int64_t vs) {
Broadcast 指令|FMA 计算|访存开销 // Configure Vector Type.
auto vectorTy = mlir :: VectorType :: get ({vs}, f32);
硬件信息的静态提取 程序开销的动态测量 rw. create<affine :: AffineVectorLoadOp>> (..., vectorTy, ...);
... ...
基于 Img2Col 变换的卷积优化算法 rw. create<affine :: AffineVectorStoreOp> (..., vectorTy, ...);
Registers,Cache… Ld/St,FMA,Broadcast… ... ...
Img2Col 变换|矩阵乘法算子|访存开销 }
(b) AutoConfig 机制的设计、实现与集成
图 2 AutoConfig 的概述、设计、实现与集成