
Page 45 - 《软件学报》2024年第6期
P. 45
沈天琪 等: DDoop: 基于差分式 Datalog 求解的增量指针分析框架 2621
4) PMD 是一个源代码分析器, 用于检测和识别 Java 代码中的潜在问题和不规范编码风格.
5) CheckStyle 是一个用于检查 Java 源代码是否符合代码标准或验证规则集的工具.
表 1 实验数据集
Project init #commits freq LOC ΔLOC (avg/max) Δmet (avg/max) Δfile (avg/max)
Jedis 5359c37 2 248 3 per day 102k 266/2 692 45/387 6/27
ErrorProne 3dd2abc 6 056 1 per day 317k 104/924 11/77 3/21
ZooKeeper 5b6823a 2 504 1 per week 184k 122/735 11/74 5/31
PMD 792fe44 26 317 10 per week 224k 151/1 720 2/21 4/33
CheckStyle 7007bef 12 794 10 per day 318k 270/2 027 7/73 7/23
3.2 RQ1: 性能
为了评估我们的 DDoop 增量指针分析框架在代码变更频繁的场景下的性能, 我们将 DDoop 增量框架与原
始 Doop 框架进行对比. 具体而言, 对于 20 次连续代码提交编译生成的 20 个版本 jar 包, 我们的 DDoop 增量框架
和原始 Doop 框架将会依次分析每一个版本, 并且统计对每一个版本的分析所需要的时间. 对于我们的增量分析
框架, 对第 1 个版本 jar 包的分析是全量分析, 后续的 19 个版本则是增量分析; 而对于原始 Doop 框架, 它对于 20
个版本 jar 包的处理方式完全相同, 每一次都是从头开始全量分析.
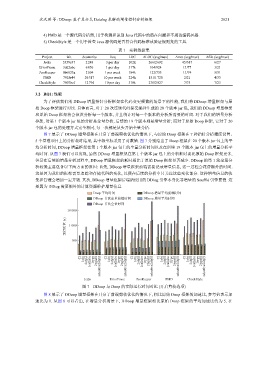
图 7 展示了 DDoop 增量框架在开启了前端剪枝优化的情况下, 与原始 Doop 框架在 7 种指针分析精度设置、
5 个基准项目上的分析耗时结果, 其中纵坐标采用了对数轴. 图 7 分别给出了 Doop 框架在 20 个版本 jar 包上的平
均分析时间, DDoop 增量框架在第 1 个版本 jar 包上的全量分析时间以及在后续 19 个版本 jar 包上的增量分析平
均时间. 从图 7 我们可以发现, 虽然 DDoop 增量框架在第 1 个版本 jar 包上的分析耗时要比原始 Doop 框架更多,
但是在后续的增量分析过程中, DDoop 增量框架的耗时相比于原始 Doop 框架显著减少. DDoop 的第 1 轮全量分
析较慢主要包含以下两方面的原因: 首先, DDoop 增量框架前端需要记录增量信息, 这一过程会花费额外的时间.
这是因为我们的框架需要追踪和存储代码的变化, 以便在后续的分析中只关注这些变化部分. 这种增量信息的收
集和管理会增加一定开销. 其次, DDoop 增量框架后端所使用的 DDlog 引擎本身比非增量的 Soufflé 引擎要慢. 这
是因为 DDlog 需要额外的计算资源维护增量信息.
1type
Doop 平均时间 DDoop 增量平均前端时间
DDoop 首次全量前端时间 DDoop 增量平均时间
DDoop 首次全量时间
10 000
运行时间 (s) 1 000
100
Cl 1obj 2objH 1callsite 1type 2typeH selective2objH Cl 1obj 2objH 1callsite 2typeH selective2objH Cl 1obj 2objH 1callsite 1type 2typeH selective2objH Cl 1obj 2objH 1callsite 1type 2typeH selective2objH Cl 1obj 2objH 1callsite 1type 2typeH selective2objH
Jedis ErrorProne ZooKeeper PMD CheckStyle
图 7 DDoop 与 Doop 的实际运行时间对比 (开启剪枝选项)
图 8 展示了 DDoop 增量框架在开启了前端剪枝优化的情况下, 相比原始 Doop 框架的加速比, 参考值表示加
速比为 1. 从图 8 可以看出, 在增量分析场景下, DDoop 增量框架相比原始 Doop 框架的平均加速比约为 5. 在