
Page 389 - 《软件学报》2024年第6期
P. 389
胡梓锐 等: HTAP 数据库系统数据共享模型和优化策略 2965
一致性模型只约束同步的粒度和范围, 但不限制实现方式, 各类 HTAP 数据库系统可以按照负载的需求自主选择
同步方式. 具体来说, 在同步粒度和范围的约束上, 线性一致性需要以细粒度的版本标识号方式进行数据同步, 而
对于顺序一致性而言, 则可以放松同步粒度, 以批处理的方式同步数据, 会话一致性则进一步可以在每个会话内独
立按需进行数据同步.
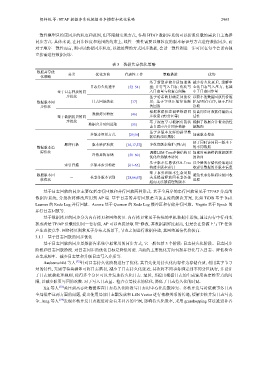
表 3 数据共享优化策略
数据共享优 分类 优化方向 代表性工作 策略描述 优势
化策略
基于新型存储介质加速落 减少持久化延迟, 缓解中
日志持久化速率 [52–54] 盘; 并行写入日志; 优化写 心化日志写入压力, 也减
基于日志回放的同 入日志量与检查点间隔 小了日志同步量
步优化 基于哈希映射确定回放位 以较小的数据回放代价维
数据版本同 日志回放效率 [17] 置; 基于字典压缩算法顺 护AP列存有序, 便于后续
步优化 次回放 读取
根据数据状态调整数据同 提高同步时数据传输的灵
数据拷贝粒度 [46]
基于数据拷贝的同 步粒度 (表/分区等) 活性
步优化 基于深度学习根据负载状 缓解了数据合并带来的性
数据合并时间选取 [55]
态自适应合并同步数据 能瓶颈
基于多版本友好的新型数
多版本组织方式 [29,56] 加速版本搜索
据结构组织数据
便于同时访问同一版本下
顺序扫描 版本维护粒度 [16,17,57] 多粒度版本维护 (列/表)
数据版本追 的不同数据
踪优化 调整LSM-Tree存储结构以 加速对更新鲜的数据版本
冷热异构存储 [58–60]
优化冷热版本访问 的访问
基于版本信息优化B-Tree 以少量的存储代价加速读
索引扫描 多版本索引构建 [61–65]
构建多版本索引 取索引数据的多版本信息
基于事务和版本生命周期
数据版本回 - 长事务版本识别 [28,66,67] 关系提前释放因长事务挂 避免长事务阻碍垃圾回收
收优化 进程
起而无法被清理的版本
点生成频率、减少日志量和升级日志写入介质等.
基于日志回放的同步主要包括串行回放和并行回放两种形式. 基于全局序的串行回放常见于 TP/AP 分离的
数据库系统, 分批次将修改应用到 AP 端. 基于日志的并行回放是当前主流的解决方案, 比如 TiDB 基于 Raft
Learner 的 Redo Log 并行回放、Aurora 基于 Quorum 的 Redo Log 缓冲区和存储并行回放、Vegito 基于 Epoch 的
并行日志回放等.
基于数据拷贝的同步分为内存拷贝和网络拷贝. 内存拷贝常见于传统的单机数据库系统, 通过内存中行列变
换或者是 TP/AP 负载使用同一套存储, AP 可以直接读取 TP 修改, 其数据新鲜度最高, 但是会在资源上与 TP 任务
产生直接竞争. 网络拷贝则常见于分布式场景下, 节点之间进行数据传递, 其网络通信代价较高.
3.1.1 基于日志回放的同步优化
基于日志回放的同步是数据库系统中最常用的同步方式, 它一般包括 3 个阶段: 日志持久化阶段、日志同步
阶段和日志回放阶段. 对日志同步的优化目标是降低时延. 当前的主要优化方向包括并行化写入日志、降低检查
Haubenschild 等人 [52] 针对日志持久化阶段进行了优化. 其首先使用持久化内存作为存储介质, 利用其字节寻
址的特性, 无需等待块满即可将日志落盘, 减少了日志持久化延迟; 其次将不同事务绑定到不同分区执行, 并设计
了日志依赖处理规则, 使得多个分区可以并发地持久化日志. 最后, 其提出根据日志的生成速度决定检查点的间
隔, 以减少脏页写回的次数. 对于写入日志量、检查点等技术的优化, 降低了日志持久化的时延.
Xia 等人 [53] 关注到高吞吐数据库在日志持久化阶段写日志时中心化发戳冲突、多核并发写时依赖事务日志
全局排序这两方面的问题, 提出使用局部日志戳发放和 LSN Vector 进行依赖关系的传递, 缓解多核并发日志写竞
争. Jung 等人 [54] 发现多核并发日志推进时会有未补齐的空洞, 影响持久化效率, 采用 grasshopping 算法推进补齐