
Page 297 - 《软件学报》2024年第6期
P. 297
周光有 等: 基于关系图卷积网络的代码搜索方法 2873
(2) Facebook 团队提出的 UNIF [31] 通过词嵌入技术 fastText 嵌入代码和文本, UNIF 使用可学习的嵌入来映射
代码和查询, 为了生成它们的表示, 代码片段的所有令牌嵌入都通过注意力加权聚合, 余弦距离用作相似度度量.
将其作为基线模型进行实验时, 设置词嵌入的维度为 100.
(3) DeepCS 从 [8] 3 个方面挖掘代码的语义信息: 方法名、代码中包含的 token、API 调用序列. 然后作者使用
LSTM 或 MLP 对 3 种不同的序列编码后融合, 对文本查询使用 RNN 嵌入. 由于他们对 API 调用序列的提取方法
是基于 Java 语言特有的启发式方法, 对其他编程语言不起作用. 因此在实验中只使用方法名和代码标记作为源代
码的语义特征.
(4) GraphSearchNet [15] 用双向门控图神经网络 (BiGGNN) 训练了两个独立的程序编码器和查询编码器, 并通过
多头注意力机制补充代码和文本的全局依赖信息. 作者将图的节点个数限制在 200 个, 而本文将图的节点个数限
制在 300 个, 实验仍然遵循作者的原始设置.
3.5 与基线模型的对比
3.5.1 在测试集上的实验
为了证明我们提出的方法的有效性, 本节通过比较在 FB-Java 数据集和 CSN-Python 数据集上的平均倒数排
名 MRR 和在 k 处的成功率 S@k 来定量评估模型. 表 4 和表 5 给出了与 7 种基线方法在两个公开数据集上的实验
数据对比. 黑体的数据表示最好的结果, 带有下划线的数据表示次好的结果. 最后两行 GraphCS (margin loss) 和
GraphCS (circle loss) 表示将损失函数分别设置为 margin loss 和 circle loss [32] 的实验结果.
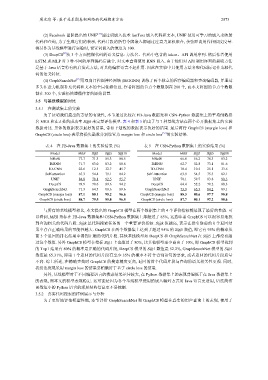
表 4 在 FB-Java 数据集上的实验结果 (%) 表 5 在 CSN-Python 数据集上的实验结果 (%)
Model MRR S@1 S@5 S@10 Model MRR S@1 S@5 S@10
NBoW 77.7 71.3 85.3 88.5 NBoW 66.0 56.2 78.3 83.2
BiRNN 71.7 63.0 83.2 88.6 BiRNN 62.7 52.8 73.1 81.6
1D-CNN 22.6 12.3 32.7 45.7 1D-CNN 18.4 10.5 25.1 33.6
Self-attention 65.3 54.4 79.1 84.2 Self-Attention 63.9 54.5 75.3 82.1
UNIF 84.8 78.1 92.5 95.7 UNIF 70.1 59.7 83.8 90.3
DeepCS 的概率是正确的代码片段, DeepCS 88.3
64.4
DeepCS
78.2
52.2
94.2
70.6
78.9
89.6
GraphSearchNet 71.3 64.5 88.6 89.6 GraphSearchNet 73.9 65.3 84.2 89.1
GraphCS (margin loss) 87.1 80.1 95.2 96.6 GraphCS (margin loss) 88.3 80.6 97.7 98.8
GraphCS (circle loss) 86.7 79.5 95.0 96.5 GraphCS (circle loss) 87.7 80.1 97.2 98.6
与所有的基线模型相比, 本文提出的 GraphCS 模型在两个数据集上的 4 个评价指标都展现了最好的性能. 可
以看到, MRR 指标在 FB-Java 数据集和 CSN-Python 数据集上都超过了 85%, 这意味着 GraphCS 可以很容易地找
到查询相关的代码片段. S@k 是代码搜索任务的一个重要评价指标. S@k 值越高, 表示在排名靠前的 k 个返回结
果中存在正确结果的可能性越大. GraphCS 在两个数据集上达到了超过 95% 的 S@5 数值, 即它有 95% 的概率从
前 5 个返回的排名结果中得到正确的代码片段. 其他基线模型如 DeepCS 和 GraphSearchNet 在 S@5 上都没有超
过这个数值. 另外 GraphCS 模型在指标 S@1 上也超过了 80%, 比其他模型至少高出了 10%, 即 GraphCS 模型找到
的 Top1 结果有 80% 模型的 S@1 数值是 52.2%, GraphSearchNet 模型的 S@1
数值是 65.31%, 即第 1 个返回的代码片段有至少 35% 的概率不符合查询语句的要求, 或者返回的代码片段质量
不高. 综上所述, 在精确查找时 GraphCS 的搜索精度更高, 返回的首个代码片段与查询的语义相关性更强. 同时,
我们也发现采用 margin loss 的结果要稍微好于基于 circle loss 的结果.
另外, 基线模型对于不同编程语言的搜索结果差异较大, 在 Python 数据集上的表现普遍低于在 Java 数据集上
的表现, 而本文的模型表现稳定. 这可能是因为各个基线模型使用的嵌入编码方式对 Java 语言更适用, 语法简洁
函数短小的 Python 语言的深层结构信息更不易挖掘.
3.5.2 真实代码搜索的样例展示与分析
为了更好地评估模型性能, 本节评价 GraphSearchNet 和 GraphCS 模型在真实的用户查询上的表现, 使用了