
Page 207 - 《软件学报》2024年第6期
P. 207
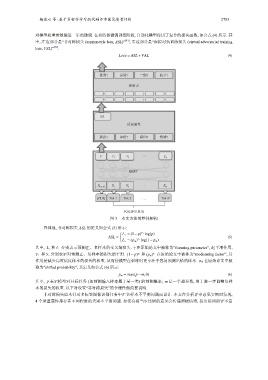
杨岚心 等: 基于多标签学习的代码评审意见质量评价 2783
对模型权重参数做进一步的微调. 在有监督微调训练阶段, 自动化模型使用了复合的损失函数, 如公式 (4) 所示. 其
中, 左边部分是“非对称损失 (asymmetric loss, ASL)” [41] , 右边部分是“虚拟对抗训练损失 (virtual adversarial training
loss, VAL)” [42] .
Loss = ASL+VAL (4)
优秀? ਅݺ? ၂Ϯ? 较差?
映射表
L − 分别表示预测正、负样本的交叉熵损失.
0/1
质量属性
ࡹၰ? ࡎ? ၐ໙? ౦࿂?
…
C T 1 T 2 T N
BERT
…
E [CLS] E 1 E 2 E N
[CLS] Tok 1 Tok 2 … Tok N
代码评审意见
图 3 本文方法的整体架构
具体地, 非对称损失 ASL 的定义如公式 (5) 所示:
L + = (1− p) log(p)
γ +
(5)
ASL =
L − = (p m ) log(1− p m )
γ −
其中, L + 和 γ 在原始论文中被称为“focusing parameter”, 起平滑作用,
γ + 和 γ − 分别表示对预测正、负样本的损失的平滑. (1− p) γ + 和 (p m ) γ − 在原始论文中被称为“modulating factor”, 其
p m 在原始论文中被
作用是减少高置信度样本的损失的权重, 从而使模型在训练时更专注于容易预测出错的样本.
称为“shifted probability”, 其定义如公式 (6) 所示:
p m = max(p−m,0) (6)
p 表示模型对目标任务 m 是一个超参数, 用于进一步调整负样
其中, (如预测输入样本属于某一类) 的预测概率;
本的损失的权重. 以下对设置“非对称损失”的合理性做简要说明.
非对称损失原本针对多标签图像识别任务中正负样本不平衡问题而设计. 本文在分析评审意见实例时发现,
4 个质量属性都存在不同程度的类别不平衡问题. 如仅有相当少比例的意见会传递消极情绪, 提出疑问的评审意