
Page 118 - 《软件学报》2024年第6期
P. 118
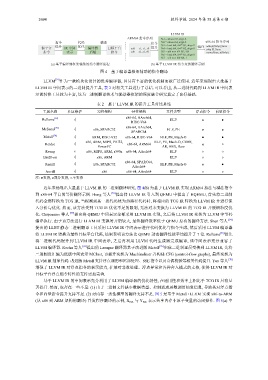
2694 软件学报 2024 年第 35 卷第 6 期
LLVM IR
ARM64 指令序列 %1 = alloca i64, align 8
指令 代码 编译 指令 %2 = alloca i64, align 8 x86-64 指令序列
提升 优化 %3 = load i64, i64* %1, align 8 编译 addq x(%rbp),%rax
源平台 IR 中间 编译器 目标平台 add x1, x1, x0 提升 %4 = load i64, i64* %2, align 8 subq $1,%rax
指令 表示 后端 指令 sub x1, x1, #1 %5 = add nsw i64 %3, %4 movq %rax, x(%rbp)
%6 = load i64, i64* %1, align 8
%7 = sub nsw i64 %6, 1
(a) 基于编译器框架辅助的指令翻译流程 (b) 基于 LLVM IR 指令变换翻译示例
图 4 基于编译器框架辅助的指令翻译
LLVM [74] 作为一款模块化设计的优秀编译器, 因具有丰富的优化机制而被广泛使用. 近年来涌现出大批基于
LLVM IR 中间表示的二进制提升工具, 表 2 对相关工具进行了总结. 可以看出, 从二进制代码到 LLVM IR 中间表
示的转换工具较为丰富, 这为二进制翻译技术与编译器框架的深度融合研究奠定了良好基础.
表 2 基于 LLVM IR 的提升工具对比总结
工具名称 社区维护 32位架构 64位架构 文件类型 浮点指令 向量指令
[38] x86-64, AArch64,
Rellume √ - ELF o ●
RISC-V64
McSema [75] √ x86, SPARC32 x86-64, AArch64, ELF, PE o o
SPARC64
Mctoll [76] √ ARM, RISC-V32 x86-64, RISC-V64 ELF, PE, Mach-O ● ●
x86, ARM, MIPS, PIC32, ELF, PE, Mach-O, COFF,
Retdec √ x86-64, ARM64 o ○
PowerPC AR, HEX, Raw
Revng × x86, MIPS, ARM, s390x x86-64, AArch64 ELF ○ ○
Bin2llvm √ x86, ARM - ELF ○ ○
x86-64, SPARC64,
Remill √ x86, SPARC32 ELF, PE, Mach-O o ●
AArch64
Anvill √ x86 x86-64, AArch64 ELF ○ ○
注: ●支持, o部分支持, ○不支持
Lasagne 翻译器基于改进版
近年来涌现出大量基于 LLVM IR 的二进制翻译研究, 图 4(b) 为基于 LLVM IR 实现 ARM64 加法与减法指令
到 x86-64 平台的等价翻译示例. Hong 等人 [20] 提出将 LLVM IR 引入到 QEMU 中提出了 HQEMU, 首先将二进制
代码全部转换为 TCG IR, 当探测到某一段代码块为热路径代码时, 将相应的 TCG IR 转换为 LLVM IR 并进行深
入分析与优化. 然而, 该方法受到 TCG IR 优化不足的限制, 无法对未变换为 LLVM IR 的 TCG IR 开展细粒度优
化. Chipounov 等人 [77] 提出将 QEMU 中间表示全部采用 LLVM IR 实现, 之后将 LLVM IR 变换为 LLVM 字节码
编译执行. 由于该方法进行 LLVM IR 变换时开销较大, 最终翻译效率低于 QEMU 原有的翻译方法. Shen 等人 [54]
提出的 LLBT 静态二进制翻译工具采用 LLVM IR 中间表示进行代码优化与指令生成, 然后采用 LLVM 编译器
将 LLVM IR 转换为最终目标平台代码, 结果表明该方法比 QEMU 动态翻译性能平均提升了 7 倍. Rellume [38] 首先
将二进制代码提升到 LLVM IR 中间表示, 之后再利用 LLVM 代码生成器完成编译, 该中间表示充分兼容了
LLVM 编译器. Rocha 等人 [41] 提出的 Mctoll [76] 完成二进制逐层变换到 LLVM IR, 先将
二进制反汇编为低级中间表示 MCInst, 再提升变换为 MachineInstr 并构建 CFG (control-flow graphs), 最终变换为
LLVM IR 抽象代码. 改进版 Mctoll 支持浮点调用和尾部处理、SSE 指令以及奇偶校验等相关代码提升. You 等人 [78]
增强了 LLVM IR 对浮点指令的表示能力, 扩展对非数处理、浮点异常和各种舍入模式的支持, 使得 LLVM IR 对
目标平台浮点指令特性的支持更加完善.
基于 LLVM IR 的中间表示充分利用了 LLVM 编译器的优化特性, 在通用性和效率上相比于 TCG IR 具有显
著提升. 然而, 也存在一些不足: (1) 由于二进制文件缺少数据类型、控制流或函数调用抽象信息, 导致其对浮点指
令和向量指令提升支持不足. (2) 对内存一致性模型的翻译支持不足. 图 5 是基于 Mctoll+LLVM 实现 x86-to-ARM
(从 x86 到 ARM 架构的翻译) 并发程序翻译的示例, X N 与 Y N 表示共享内存非原子变量的访问操作. 图 5(a) 中
A
A