
Page 361 - 《软件学报》2024年第4期
P. 361
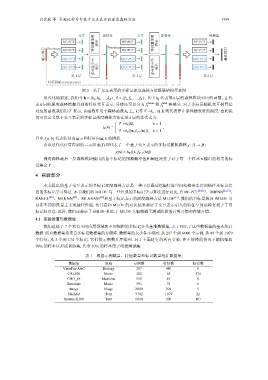
吕沈欢 等: 多标记学习中基于交互表示的深度森林方法 1939
交互 新特征 交互 新特征 预测值
RF-PCT 特征置信度 表示 Bootstrap RF-PCT 特征置信度 表示 RF-PCT
输入特征 Bootstrap ERF-PCT ERF-PCT … ERF-PCT 最终预测
RF-PCT
RF-PCT
RF-PCT
ERF-PCT 多标签分布 表示 ERF-PCT 多标签分布 表示 ERF-PCT
第 1 层 第 2 层 第 k 层
特征粘贴 (concatenate)
图 2 基于交互表示的多标记深度森林方法级联结构示意图
k
形式化地描述, 我们令 h = {h 1 ,h 2 ,...,h K } f = { f 1 , f 2 ,..., f K } , 其中 h k 代表第 层的森林模块对应的函数, f k 代
,
f feature f label 两部分. 对于多标记随机交互树算法
表 k 层的深度森林挖掘得到的特征交互表示, 具体还可以分为 k 和 k
对应的函数我们用 T 表示, 该函数作用于森林函数 h k 上, 记作 T ◦h k . 而 K 则代表停止条件触发时的深度. 由此我
们可以定义基于交互表示的多标记深度森林方法在第 k 层的迭代式为:
T ◦h k (x), k = 1
,
f k (x) =
T ◦h k ([x, f k−1 (x)]), k > 1
其中, [a, b] 代表特征向量 a 和特征向量 b 的拼接.
由该迭代式计算得到的二元组 (h,f) 即代表了一个基于交互表示的多标记随机森林 g : X → Y :
g(x) = h K ([x, f K−1 (x)]).
x 输出的相关的标
深度森林最后一层森林模块输出的各个标记的预测概率值和阈值决定了对于每一个样本
ˆ Y .
记集合
4 实验部分
本文提出的基于交互表示的多标记深度森林方法是一种可以通过挖掘特征空间结构来丰富训练样本标记信
息的多标记学习算法. 本节我们将 iMLDF 与一些经典的多标记学习算法进行对比, 有 RF-PCT [24,25] 、DBPNN [26,27] 、
RAKEL [28] 、MLKNN [29] 、MLARAM [30] 和基于标记表示的深度森林方法 MLDF [13] . 我们的目标是验证 iMLDF 可
以在不同的度量上实现最佳性能, 尤其是和 MLDF 的对比结果验证了交互表示引入的特征空间结构有利于丰富
标记间信息. 此外, 我们还验证了 iMLDF 相比于 MLDF 大幅缩减了测试阶段的计算开销和存储开销.
4.1 实验设置与数据集
我们选择了 7 个来自不同应用领域和不同规模的多标记分类基准数据集. 表 1 列出了这些数据集的基本统计
数据. 所有数据集均来自多标记数据集的存储库. 数据集的大小各不相同: 从 207 个到 6 000 个示例, 从 49 个到 1 079
个特征, 从 5 个到 174 个标记. 它们按示例数升序排列. 对于下面进行的所有实验, 在不替换的情况下随机抽取
70% 的样本以形成训练集, 其余 30% 的样本用于创建测试集.
表 1 根据示例数量、特征数量和标记数量统计数据集.
数据集 领域 示例数 特征数 标记数
VirusPse-AAC Biology 207 440 6
CAL500 Music 502 68 174
CHD_49 Medicine 555 49 6
Emotions Music 593 72 6
Image Image 2 000 294 5
Slashdot Text 3 782 1 079 22
Reuters-K500 Text 6 000 500 103