
Page 227 - 《软件学报》2024年第4期
P. 227
万常选 等: 主题方面共享的领域主题层次模型 1805
第 2 层节点的迭代过程是顺序执行的, 而在迭代生成第 1 层节点的过程中, 每篇文档的主题分布是无法确定的, 因
此在比较模型复杂度时, 模型的迭代次数描述的是每个模型第 2 层节点生成的迭代过程, 每次迭代的复杂度也是
第 2 层各分支节点在该迭代次数中复杂度的平均值.
2 300
hLDA WEDTM rHDP hLDA WEDTM rHDP
12 000
2 000
comp 8 000 comp 1 700
1 400
4 000
1 100
0 800
1 6 11 16 21 26 31 36 41 1 6 11 16 21 26 31
迭代次数 迭代次数
(a) 财经微博文本 (b) 20NewsGroup
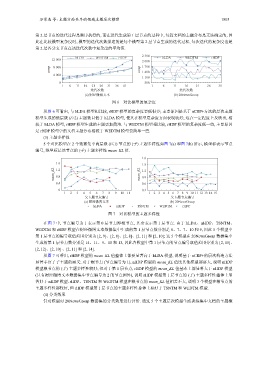
图 6 对比模型的复杂度
从图 6 可看出, 与 hLDA 模型相比较, rHDP 模型的复杂度要低很多; 主要原因是基于 nCRP+方法的层次主题
模型生成的低层级 (l≥2) 主题数目低于 hLDA 模型, 使其在模型复杂度方面表现较好; 这在一定程度上反映出, 相
较于 hLDA 模型, rHDP 模型生成的主题更加简洁. 与 WEDTM 模型相比较, rHDP 模型的复杂度低一些, 主要原因
是 rHDP 模型中的文档主题分布相较于 WEDTM 模型要简单一些.
(3) 主题多样性
5 个对比模型在 2 个数据集中高层级 (l≤1) 节点的 (子) 主题多样性如图 7(a) 和图 7(b) 所示, 横坐标表示节点
编号, 纵坐标是该节点的 (子) 主题多样性 mean_KL 值.
1.8
1.6 1.5
mean_KL 1.2 mean_KL 1.2
0.8
0.9
0.4 0.6
0 0.3
1 2 3 4 5 6 7 8 9 10 11 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
父主题节点编号 父主题节点编号
(a) 财经微博文本 (b) 20NewsGroup
hLDA nHDP TSNTM WEDTM rHDP
图 7 对比模型的主题多样性
在图 7 中, 节点编号为 1 表示第 0 层节点即根节点, 其余表示第 1 层节点. 由于 hLDA、nHDP、TSNTM、
WEDTM 和 rHDP 模型在财经微博文本数据集中生成的第 1 层节点数分别是 8、7、7、10 和 9, 因此 5 个模型中
第 1 层节点的编号取值范围分别为 [2, 9]、[2, 8]、[2, 8]、[2, 11] 和 [2, 10]; 这 5 个模型在 20NewsGroup 数据集中
生成的第 1 层节点数分别是 14、11、9、10 和 13, 因此各模型中第 1 层节点的节点编号取值范围分别为 [2, 15]、
[2, 12]、[2, 10] 、[2, 11] 和 [2, 14].
从图 7 可看出, rHDP 模型的 mean_KL 值整体上都要显著高于 hLDA 模型, 说明基于 nCRP+的层次构造方法
显著丰富了子主题的涵义; 对于根节点 (节点编号为 1), nHDP 模型的 mean_KL 值比其他模型都要大, 说明 nHDP
模型根节点的 (子) 主题多样性较好; 但对于第 1 层节点, rHDP 模型的 mean_KL 值基本上都显著大于 nHDP 模型
(只有财经微博文本数据集中节点编号为 2 的节点例外), 说明 rHDP 模型第 1 层节点的 (子) 主题多样性整体上显
著好于 nHDP 模型. rHDP、TSNTM 和 WEDTM 模型在根节点的 mean_KL 值相差不大, 说明 3 个模型在根节点的
主题多样性都较好, 但 rHDP 模型第 1 层节点的主题多样性总体上要好于 TSNTM 和 WEDTM 模型.
(4) 分类效果
针对模型对 20NewsGroup 数据集的分类效果进行评价. 通过 5 个主题层次模型生成训练集中文档的主题概