
Page 37 - 《软件学报》2021年第11期
P. 37
陶传奇 等:编程现场上下文深度感知的代码行推荐 3363
表 6 是 DA4CLR、PHOG 和 RNN 这 3 种方法的最佳推荐结果在所有结果中的位置信息的比较.Frank 和
LRank 分别是最好的推荐结果在所有推荐结果中最靠前和最靠后的位置信息.从表中我们可以看出,最靠前的
情况,3 种方法都有在排在第一的位置得到最佳结果的情况;而对于靠后的最佳推荐结果同样如此.原因在于,对
于本文的方法,虽然有针对推荐列表的二次排序,但是对于多次推荐,仍然无法避免有最佳推荐项在推荐列表靠
后位置的情况,只能在一定程度上避免这种较差结果产生.当推荐结果项数为 10 时,RNN 和 PHOG 方法的 MRR
得分小于 DA4CLR 方法,结合上文在 BLEU 指标上的结果,更加充分体现了本文利用语义信息来进行推荐列表
的二次排序是比较有效的.MRR 值越大,说明推荐项的整体优先级排序情况越符合用户需求.因此,本文方法能
够将用户满意的推荐项排在推荐结果中靠前的位置.从方法的综合效果考虑,我们的方法具有更大的优势.
Table 6 Ranking information of recommended results for three different methods
表 6 3 种不同方法的最佳推荐结果排序信息
指标
方法
FRank LRank MRR
DA4CLR 1 10 0.306 6
RNN 1 10 0.274 1
PHOG 1 10 0.295 3
对问题 2 的回答:从上述比较结果可以看出,本文的代码行推荐方法在准确率上对比类似相关方法有一定
的提升.这主要是模型的深度学习能力以及二次排序所带来的结果,因为经过数据统一化之后的数据具有更高
质量,更加容易进行上下文模式学习,适合利用深度学习模型对隐含上下文模式进行深度学习.此外,二次排序
工作则对生成结果不太好的情况进行了补充,所以本文模型对比类似工作有一定的优越性.并且,考虑到准确率
和更加一般的适用性,上述实验结果表明,与具有类似功能的方法相比,本文方法能够在不降低推荐准确率的情
况下,仍然保证相关性较高的代码行在推荐结果中的位置也相对靠前.
4.2.3 对问题 3 的回答
我们设计的第 3 个实验,是为了测试本文方法在不同参数条件下的推荐情况.检测的参数主要是上下文代
码行数 n 和推荐结果数 k.如我们前面所说,上下文代码行数 n 代表着对已有信息的获取程度,它的不同,可能直
接对方法性能产生影响.而合适推荐结果数 k 则意味着,可以在我们方法的推荐效果和推荐效率之间取得最佳
平衡.所以,对这两个参数进行研究,以找到最佳取值,对我们的方法来说是很有必要的.
根据 n 的可能取值,我们将 n 分为设置 1~5 进行实验.对 n 进行实验时,将 k 值设为 10.对于 k,我们设置为 1,5,8
和 10 分别进行测试,来观察推荐结果数对推荐结果的影响.对 k 进行测试时,将 n 值设置为 2.所有的数据都经过
前面所定义的第 2 等级的统一化处理,并且去掉一些不会影响结构的字符.用于测试的实例数共 100 个,全部采
用人工观测的方式进行推荐结果有效性判断.
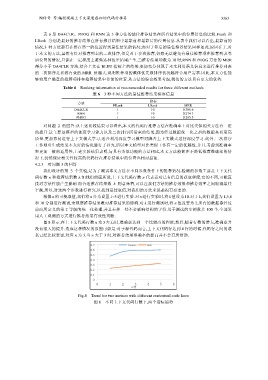
图 8 显示,在上下文代码行数 n 为 3 左右时,准确率达到一个比较高的程度;然后,随着行数的增大,准确率并
没有很大的提升.造成这种情况的原因可能是:对于源代码而言,上下文代码行达到 4 行的时候,代码行之间的联
系已经比较紧密,对应 n 为 3.当 n 大于 3 时,对推荐结果准确率的提高并不会有所帮助.
0.7 Precision MRR
0.6
0.5
0.4
0.3
0.2
0.1
0
0 1 2 3 4 5 6
n 行
Fig.8 Trend for two metrics with different contextual code lines
图 8 不同上下文代码行数下,两个指标趋势