
Page 265 - 《软件学报》2021年第11期
P. 265
杨良怀 等:面向大数据流的分布式索引构建 3591
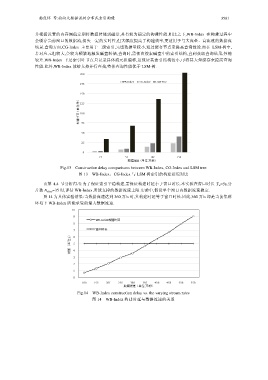
并根据设置的内存阈值定期将数据转储到磁盘,具有较为稳定的构建性能.相比之下,WB-Index 在构建过程中
会缓存当前窗口的数据流,损失一定的实时性,但大幅度提高了构建效率,更适用于与大流量、高流速的数据流
场景.查询方面,CG-Index 主要用于二级索引,元组数据量较小,通过缓存节点来提高查询性能.而在 LSM-树中,
若对应元组较大,会较为频繁地触发磁盘转储,查询时,需依次搜索磁盘中的索引结构,直到获取查询结果,性能
较差.WB-Index 下层索引叶节点只记录具体流元组偏移,这保证其索引结构较小,可将其大量缓存来提高查询
性能.此外,WB-Index 能够支持并行查找,整体查询性能优于 LSM-树.
Fig.13 Construction delay comparisons between WB-Index, CG-Index and LSM tree
图 13 WB-Index、CG-Index 与 LSM 树索引的构建延迟对比
由第 4.4 节分析得出:为了保证索引平稳构建,需保证构建时延小于窗口时长.本实验在窗口时长 T w =5s,分
片数 N slice =35 时,评估 WB-Index 所能支撑的数据流速上限.实验中,假设单个窗口内数据流速稳定.
图 14 为具体实验结果:当数据流速达到 360 万/s 时,其构建时延等于窗口时长.因此,360 万/s 即是当前集群
环境下 WB-Index 所能承受的最大数据流速.
Fig.14 WB-Index construction delay vs. the varying stream rates
图 14 WB-Index 构建时延与数据流速的关系