
Page 255 - 《软件学报》2021年第11期
P. 255
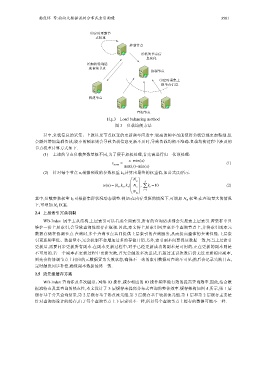
杨良怀 等:面向大数据流的分布式索引构建 3581
③定时更新节
点权重
控制节点
②监听节点信
息变化
④加权轮询选
取查询节点
协调节点
①定时采集上
报节点信息
构建节点
查询节点
Fig.3 Load balancing method
图 3 负载均衡方法
其中,负载信息的采集、上报以及节点权重的更新频率应适中:较高的频率虽能使得负载管理更加精细,但
会额外增加集群负载;较小的频率则会导致负载信息更新不及时,导致负载均衡不准确.负载均衡过程中涉及的
节点权重计算方式如下.
(1) 上述的节点负载参数量级不同,为了便于加权处理,首先需进行归一化预处理:
x− min( )x
x norm = (1)
x −
max( ) min( ) x
(2) 针对每个节点 n,根据预设的参数权重 k i ,计算出最终的权重值,如公式(2)所示.
⎛ N q ⎞ 3
⎜
() =
wn ( , , ) N ⎟ , ∑ k = 10 (2)
k k k
1 2 3 ⎜ c ⎟ i
⎜ ⎟ i= 1
⎝ N m ⎠
其中,负载参数权重 k i 可根据集群状况动态调整.例如:在内存受限的情况下,可增加 N m 权重;在查询量大的情况
下,可增加 N q 权重.
2.4 上层索引冗余机制
WB-Index 属于主从结构,上层索引可以看成全局索引,所有的查询请求都会先搜索上层索引.若集群中只
维护一份上层索引,会导致查询性能存在瓶颈.因此,本文将上层索引同步至多个查询节点上,并将索引副本元
数据存储在协调节点.查询时,多个查询节点共同提供上层索引的查询服务,从而提高整体的查询性能.上层索
引更新频率低、数据量小,冗余机制不会增加过多的存储开销.另外,索引副本间要保证数据一致,每当上层索引
更新后,需要同步更新所有副本.在副本更新过程中,对于已经更新成功的副本是可用的,正在更新的副本则是
不可用的.若一个副本在更新过程中更新失败,首先会触发多次重试,若超过重试次数后仍无法更新相应副本,
则先会将协调节点上相应的元数据置为失效状态,确保不一致的索引数据对查询不可见;然后会记录失败日志,
定时触发同步补偿,确保副本数据最终一致.
2.5 流元组缓存方案
WB-Index 查询涉及多次磁盘、网络 IO 操作,减少相应的 IO 操作频率能有效的提高查询效率.因此,结合数
据流特点及其查询的热点性,本文设计了 3 层缓存来提高分布式查询的整体效率.缓存架构如图 4 所示,第 1 层
缓存基于公共查询结果,第 2 层缓存基于热点流元组,第 3 层缓存基于较新流元组.第 1 层和第 2 层缓存主要是
针对查询而设计的缓存,由于每个查询节点上下层索引不一样,所以每个查询节点上缓存的数据可能不一样.