
Page 217 - 《软件学报》2021年第11期
P. 217
欧阳佳 等:面向频繁项集挖掘的本地差分隐私事务数据收集方法 3543
1.1 事务数据隐私保护
关于事务数据的隐私保护方法得到了广泛的研究,按收集者是否可信,可分为两大类型:中心化方法与本地
化方法.其中,中心化方法又可以分为基于传统的 k-匿名分组隐私模型与差分隐私模型;本地化方法可划分为本
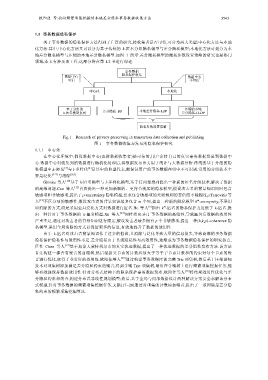
地差分隐私模型与压缩的本地差分隐私模型.如图 1 所示.差分隐私模型的隐私参数设置策略的研究也是热门
领域,本文有涉及该工作,这部分将在第 1.2 节进行综述.
事务数据
隐私保护收集
数据中心 数据中心
可信 不可信
中心化 本地化
基于分组的 压缩的本地
k-匿名模型系列 差分隐私-DP 本地差分隐私-LDP 差分隐私-CLDP
隐私参数设置策略
Fig.1 Research of privacy preserving in transaction data collection and publishing
图 1 事务数据收集与发布的隐私保护研究
1.1.1 中心化
在中心化环境中,假设数据中心(也称数据收集者)是可信的,用户会将自己的真实事务数据发送到数据中
心.数据中心对收集到的数据进行随机化处理后,将数据发布出去用于统计与大数据分析.传统的基于分组的隐
[3]
[4]
私模型中,k-匿名 与 l-多样化 是其中的典型代表,能保证用户的事务数据在组中不可识别.常用的分组技术主
要是泛化 [5−7] 与消除 [8,9] .
Ghinita 等人 [10] 基于 k-匿名模型与 l-多样化模型,基于行列重排列提出一种新的匿名分组技术,解决了数据
的高维问题.Cao 等人 [11] 首次提出一种更加新颖的、更符合现实的隐私模型,假设攻击者的背景知识同时包含
敏感项和非敏感项,提出了ρ-uncertainty 隐私模型,要求包含敏感项的关联规则的置信度不能超过ρ.Terrovitis 等
m
人 [12] 不区分项的敏感性,假设攻击者的背景知识最多包含 m 个项,提出一种新的隐私模型 k -anonymity,不采用
[5]
m
项消除的方式,而是采用全局泛化方式对数据进行匿名.He 等人 指出 k -匿名的隐私保护力度低于 k-匿名,提
出一种针对于事务数据的 k-匿名模型.Xu 等人 [13] 同样指出:由于事务数据的高维性,导致匿名后数据的效用性
严重不足.通过对攻击者的背景知识进行限定,假设攻击者最多拥有 p 个非敏感项,提出一种(h,k,p)-coherence 隐
私模型,采用全局消除的方式以保留更多的信息,有效地提升了数据的效用性.
由于 k-匿名对攻击者背景知识作了过多的假设,且消除与泛化导致大量的信息损失,导致高维的事务数据
隐私保护隐私性与效用性不足.差分隐私由于其强隐私性与高效用性,逐渐成为事务数据隐私保护的研究热点.
区性 Chen 等人 [14] 基于加拿大蒙特利尔市的真实轨迹数据,提出了一种轨迹数据的差分隐私发布方法.该方法
首先构建一棵含有噪音的前缀树,然后根据父节点的计数必须大于等于子节点计数和的约束对每个节点的噪
音进行优化,取得了非常好的效用性.欧阳佳等人 [15] 通过构建事务数据库的完整 Trie 项集树,然后基于压缩感知
技术对项集树添加满足差分隐私约束的噪音,得到含噪 Trie 项集树,最后在含噪树上进行频繁项集挖掘任务,能
够有效地保持数据效用性.针对分布式结构下的隐私保护事务数据发布,欧阳佳等人 [16] 将结果效用性优化与差
分隐私约束相结合,构建分布式非线性规划模型;然后,基于全局与局部数据设计两种解决方案安全求解该分布
式模型.针对事务数据的频繁项集挖掘任务,文献[17−20]通过对项集的计数添加噪音,提出了一系列满足差分隐
私约束的频繁项集挖掘算法.