
Page 218 - 《软件学报》2021年第10期
P. 218
3190 Journal of Software 软件学报 Vol.32, No.10, October 2021
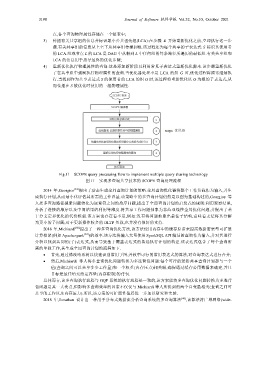
点,各个查询物理属性存储在一个链表中;
3) 传播有关共享组的信息并标识最小公共祖先组(LCA):在步骤 4 开始重新优化之前,立即执行这一步
骤.有关共享组的信息从上至下从共享组传播到根.该过程还为每个共享的子表达式 S 标识其使用者
的 LCA.组或节点 L 的 LCA 是 DAG 中从根到 L 中任何组的每条路径所遍历的最低组.有关共享组和
LCA 的信息用于指导最终的优化步骤;
4) 重新优化执行物理属性的查询:这是添加新阶段以利用常见子表达式重新优化脚本.该步骤重新优化
了在共享组中强制执行物理属性的查询.当优化器处理不是 LCA 的组 G 时,优化过程将照常继续执
行.当找到作为共享表达式 S 的使用者的 LCA 的组 G 时,该过程将重新优化以 G 为根的子表达式,从
而传播在 S 被优化时使用的一组物理属性.
Fig.11 SCOPE query processing flow to implement multiple query sharing technology
图 11 实现多查询共享技术的 SCOPE 查询处理流程
2014 年,Georgios [12] 提出了动态生成全局查询计划的策略.全局查询优化器将整个工作负载作为输入,并生
成执行计划,从而最小化评估其所需的工作总量.该策略中的多查询计划仍然是以图为基础构建的,Georgios 等
人把多查询路径搜索问题转化为运算符之间的排序问题,提出了全局查询计划的启发式的规则:利用观察结果,
分析了连接的顺序以及中间结果的利用等维度.将共享工作问题抽象为非凸双线性全局优化问题,并提出了基
于分支定界优化的代价模型.该方案也存在着不足,例如:没有将问题抽象出最佳子结构,意味着无法将其分解
为更小的子问题;对于更新操作较多的 OLTP 负载,也并没有很好的支持.
2018 年,Michiardi [60] 提出了一种多查询优化方法,该方法使用内存中的缓存原语来提高数据密集型可扩展
计算框架(例如 Apachespark [61] )的效率.该方法将输入大量使用 SparkSQL API 编写的查询作为输入,并对其进行
分析以找到共同的(子)表达式,从而导致基于覆盖表达式的备选执行计划的构建.该表达式包含了每个查询所
需的单独工作,其生成全局查询计划的流程如下.
首先,通过修改哈希树以快速识别常用子图,并枚举可行的常用表达式的算法,对查询表达式进行合并;
然后,Michiardi 等人将多查询优化问题转换为多选背包问题:每个可行的逻辑共享查询计划都与一个
值(查询之间可以共享多少工作量)和一个权重(内存压力)相关联,确保通过缓存公用数据来确定,并且
目标是最佳填充给定容量(内存限制)的背包.
总体而言,该多查询执行流程与 GQP 系统的执行流程是一致的,该方案能将多查询优化问题转换为多选背
包问题是其一大亮点,但影响多查询效率的因素不仅仅与 Michiardi 等人所提到的两个自变量相关(查询之间可
共享的工作以及内存压力).所以,该方案的可扩展性值得进一步加以研究和实验.
2018 年,Jonathan 设计出一种用于分布式数据流分析查询系统的多查询算法 [40] ,该算法将广域网络(wide-