
Page 93 - 《软件学报》2021年第9期
P. 93
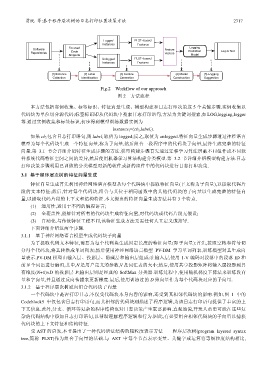
贾统 等:基于程序层次树的日志打印位置决策方法 2717
Fig.2 Workflow of our approach
图 2 方法流程
本方法包括实例收集、标签标识、特征向量生成、模型构建和日志打印决策这 5 个关键步骤.实例收集以
代码块为单位切分源代码;标签标识即从代码块中搜索日志打印语句,方法为关键词搜索,如 LOG,logging,logger
等.通过实例收集和标签标识,初步得到模型训练数据实例为
instance i =(cb i ,label i ).
如果 cb i 包含日志打印语句,则 label i 取值为 logged;反之,取值为 unlogged.特征向量生成步骤通过神经语言
模型为每个代码块生成一个特征向量,称为子向量,然后组合一段程序中的代码块子向量,最终生成完整的特征
向量.第 3.1 节会详细介绍特征生成步骤的方法.模型构建步骤首先通过迁移学习算法屏蔽不同组件或不同软
件系统代码特征空间之间的差异,然后使用机器学习算法构建分类模型.第 3.2 节详细介绍模型构建方法.日志
打印决策步骤利用已训练的分类模型对新的软件或新的组件中的代码块进行日志打印决策.
3.1 基于程序层次树的特征向量生成
特征向量生成首先利用神经网络语言模型从每个代码块中提取特征向量(下文称为子向量),以提取代码片
段的文本特征;然后,针对每个代码块,组合与其位于相同函数中的其他代码块的子向量以生成完整的特征向
量,以提取代码片段的上下文和结构特征.本文提出的特征向量生成方法具有 3 个特点.
(1) 通用性,适用于不同的编程语言;
(2) 全覆盖性,能够针对所有的代码块生成特征向量,对代码块或代码片段无假设;
(3) 自动化.与传统特征工程不同,该特征生成方法无需任何人工定义或指导.
下面详细介绍这两个步骤.
3.1.1 基于神经网络语言模型生成代码块子向量
为了提取代码文本特征,需要为每个代码块生成固定长度的特征向量(即子向量):首先,按照空格和符号切
分每个代码块,将其转换成单词列表;然后使用神经网络语言模型 PV-DM 学习单词列表,训练模型对其生成向
量表示.PV-DM 模型由输入层、投影层、隐藏层和输出层组成:在输入层,使用 1-V 编码对段落中的段落 ID 和
前 N 个词语进行编码,其中,N 是用户定义的参数,V 是词汇表的大小;然后,使用共享投影矩阵将输入层投影到具
有维度(N+1)×D 的投影层 P;输出层则是经典的 SoftMax 分类器.训练过程中,使用随机梯度下降法来训练段向
量和字向量,并且通过反向传播来更新梯度.最后,使用训练过的 D 维向量作为每个代码块对应的子向量.
3.1.2 基于程序层次树逆向组合代码块子向量
一个代码块中是否打印日志,不仅受代码块本身内容的影响,还受到其相邻代码块的影响.例如,图 1 中的
Codeblock5 中仅包含日志打印语句,而其相邻的代码块则描述了程序逻辑,为该日志打印语句提供了丰富的上
下文信息.此外,分支、循环等复杂的程序结构也对日志决策产生重要影响.直观地说,开发人员更可能在这些复
杂的代码结构中添加日志打印语句,以帮助理解程序逻辑和行为.因此,有必要组合相邻代码块的子向量以捕获
代码块的上下文特征和结构特征.
受 AST 的启发,本节提出了一种代码语法结构的粗粒度表示方法——程序层次树(program layered syntax
tree,简称 PLST)作为组合子向量的基础.与 AST 中每个节点表示变量、关键字或运算符等细粒度结构相比,